Introduction
This blog post is the continuation of the formerly shared article about BI Cloud Connector (BICC) Data Extraction File Downloading. In the previous blog post I gave an introduction into BICC and we discussed the options how to download the data extraction files from Storage Cloud or the internal built-in Universal Content Management (UCM) server. The scripts, provided in the previous blog for downloading files from UCM, are creating a directory structure that is being referred in this article again. It might be worth to mention that this specific structure is just a suggestion of a directory/file hierarchy layout, only being used in the context of these scripts. If someone plans to use own written scripts, another design of a file and directory layout would probably be chosen and could also look very differently. However, I’d like to emphasize the fact that all programs and scripts shared in this blog are using that specific structure from previous blog and won’t necessarily work if the directory structure differs.
Depending on the configuration of a BICC data extraction run in terms of data sources, we might have hundreds of files stored in UCM per extract. This might cause a tremendous amount of space consumed in UCM if not deleted after a while. As we know from the previous blog, the listing of files and their unique UCM Document ID’s is the content of the according MANIFEST.MF file. An attempt to delete these many files manually will obviously end up as a tough job and shouldn’t be seen as a serious option. It means we need a strategy to download the UCM files to a local folder or a shared (cloud) resource on a regular base, as indicated in my previous blog. Before deletion in UCM, we must also be sure that we have backups of the original ZIP files and the according MANIFEST.MF – even in case we’ve already loaded these data successfully into a Data Warehouse, Data Lake or any database service. Once files have been deleted in UCM, there are no ways to restore them and only with a local copy it will be possible to reload data if required.
This blog will suggest how to delete files in UCM by a Java program and will provide also a solution to check the existence of a file based on the information from a locally downloaded Manifest file. Out of scope are mechanisms to archive data extractions locally. This is the responsibility of a Data Administrator to initiate the UCM file deletion after data extracts were backed up.
Check Existence of Files in UCM
Local storage of files after downloading from UCM
Once a BICC data extraction run has been finished, the file MANIFEST.MF has been written to UCM as a final activity. The screenshot below shows a sample of UCM documents produced in an data extraction run via BICC:

In the previous blog, I’ve shared a shell script to download these files from UCM. The functionality of this script is explained more in detail here. This script called UCMTransferUtil.sh used a directory ../export (you had to change the script if you wanted to download into another folder!) to create a sub-directory with the unique UCM Document ID (DocID) according to the MANIFEST.MF file, as found on UCM. All data extraction files being listed in the MANIFEST.MF are stored in ZIP format beneath this folder. This is important to mention as the scripts provided in this blog have to use this specific folder name to determine the MANIFEST.MF DocID. Unfortunately, there is no other option as the MANIFEST.MF file itself doesn’t contain its own UCM DocID.
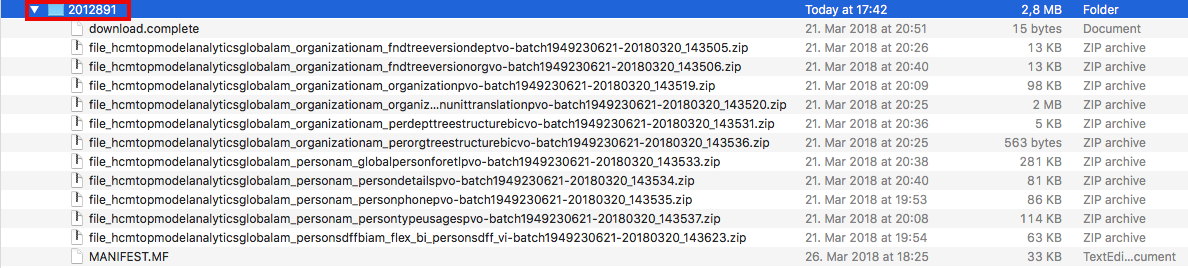
After finishing the successful download of all files from UCM another file called download.complete will be created as an indicator of a completed download. It will be used to avoid downloading files from UCM again via the script. Finally, we have created a local copy of the UCM files. Its recommended to extract the ZIP files in the folder and to backup these files afterwards. Once done, there will be no need any more keeping these files on UCM.

Over the time we might have a local file structure existing like shown in figure above. These directories, and the content from existing MANIFEST.MF files, will be used to check whether the documents are still existing in UCM. The search script in next chapter will return a status information about a documents existence on UCM for every data extraction file by its DocID. If non-existing in UCM, we can exclude this directory from deletion scope performed by script explained in detail below. The easiest method to include or exclude directories in/from scope can be achieved by keeping them in this directory structure or to move them into an archive folder once files have been deleted successfully from UCM. This activity is not part of the scripts below and would be a manual task for the system administrators.
As mentioned above the following shell script UCMTransferUtil.sh for downloading the data extraction files was published in the first version in my former blog about BICC. It uses the Java libraries and tools from Webcenter Document Transfer Utility to download files via RIDC interface from UCM. A more recent version of this script has been created in this blog to provide more flexibility for choosing the export directory on local server. The other scripts further down in this blog will use the structure for checking document existence in UCM and deletion as mentioned before.
This download script UCMTransferUtil.sh takes now two parameters:
- link to file with UCM connection properties (documented in Webcenter Document Transfer Utility docs)
- directory name for the staging of BICC extraction files to be downloaded from UCM
Before running this script one modification in code below must be performed in line 25: Please change value for environment variable UCMRidcDir, according to your specific environment requirements.
#!/bin/bash
#
# Copyright (c) 2017 Oracle and/or its affiliates. All rights reserved
#
# ujanke: 2017/08/30 initial release
# 2018/04/13 second release - parameters for connection properties and export directory, using /tmp folder
#
# This script searches for MANIFEST.MF files in UCM. If a data extraction has been previously completely downloaded
# it will skip those. By this script files will be downloaded into a directory ../export/<UCM DocID of MANIFEST.MF>. After a
# complete download a file named "download.complete" being created in that directory. It will be taken as an indicator for a completed download.
# The script reads the content of downloaded MANIFEST.MF file and downloads the zipped data extraction files belonging to this
# data extraction run. As the MANIFEST.MF file lists the MD5 checksum for every single file this script also compares these
# values to validate the correct download.
#
# Deletion of downloaded data extracts is not handled by this script.
#
# IMPORTANT: You have to set the environment variable UCMRidcDir in line 25 below to the correct directory containing the RIDC JAR files from
# Webcenter Document Transfer Utilitybefore you run this script!
#
# Two parameters are expected by this script:
# 1) link to file with UCM connection properties (documented in Webcenter Document Transfer Utility docs)
# 2) export directory
#
#
export UCMRidcDir=/foo/bar/BICC/UCMTransferUtil/ridc
if [ $# -lt 2 ]
then
echo "Wrong number of arguments!"
echo "Usage: $0 <UCM connection properties file> <starting directory>"
echo " <UCM connection properties file> : file with connection information to UCM by using the RIDC library"
echo " <export directory> : directory location for download of BICC files from UCM!"
exit 1
else
propFile=$1
exportDir=$2
fi
if [ ! -f $propFile ]
then
echo "Error: UCM connection properties file ${propFile} is non-existing ..."
exit 1
fi
if [ ! -d ${exportDir} ]
then
echo "Creating export directory ${exportDir} as non-existing ..."
mkdir ${exportDir} 2>/dev/null
dirCreationSuccess=`echo $?`
if [ ${dirCreationSuccess} -ne 0 ]
then
echo "Error: Directory ${exportDir} can't be created!"
exit 1
fi
fi
java -jar ${UCMRidcDir}/oracle.ucm.fa_client_11.1.1.jar SearchTool --propertiesFile=${propFile} --ping --quiet --silent > /dev/null 2>&1
connSuccess=`echo $?`
if [ ${connSuccess} -ne 0 ]
then
echo "Error: Connection to UCM server failed! Please check your connection information in ${propFile}"
exit 1
fi
java -jar ${UCMRidcDir}/oracle.ucm.fa_client_11.1.1.jar SearchTool \
--SortField=dID \
--SortOrder=asc \
--quiet --propertiesFile=${propFile} \
--log_file_name=/tmp/manifestSearchResults_$$.txt \
--simpleRIDCLogging \
--dDocTitle="MANIFEST.MF" \
--dSecurityGroup="OBIAImport" \
--delimiter=, \
--fields=dID,dDocName,dInDate,dOriginalName,VaultFileSize --defaultFields=false >/tmp/manifestSearchResults_$$.log 2>/tmp/manifestSearchResults_$$.err
numRows=`cat /tmp/manifestSearchResults_$$.txt | wc -l`
numRecs=`cat /tmp/manifestSearchResults_$$.txt | awk -v lastRow="$numRows" '{ if (FNR == lastRow) printf("%d\n", $1); }'`
echo "Number of Rows: ${numRecs}"
if [ ${numRecs} -eq 0 ]
then
echo "No data available! Finishing ..."
exit 255
else
echo "Running the download of recent BIACM extracts for ${numRecs} record(s) ..."
fi
i=1
while [ $i -le ${numRecs} ]
do
currDocId=`cat /tmp/manifestSearchResults_$$.txt | awk -v "current=$i" '{ if (NR == (2 + current)) print $0 }' | awk -F, '{print $1}'`
currDocDate=`cat /tmp/manifestSearchResults_$$.txt | awk -v "current=$i" '{ if (NR == (2 + current)) print $0 }' | awk -F, '{print $3}'`
echo " Saving Manifest file with UCM Doc ID : ${currDocId}"
echo " Saving Files from Extraction Date : ${currDocDate}"
if [ ! -d ${exportDir}/${currDocId} ]
then
mkdir ${exportDir}/${currDocId}
fi
if [ ! -f ${exportDir}/${currDocId}/download.complete ]
then
echo " Will extract data into directory ${exportDir}/${currDocId}"
java -jar ${UCMRidcDir}/oracle.ucm.fa_client_11.1.1.jar DownloadTool \
--propertiesFile=${propFile} \
--log_file_name=logs/manifestDownload.txt \
--outputDir=${exportDir}/$currDocId --md5 --md5lowercase \
--dID=$currDocId --RevisionSelectionMethod Latest
for a in `cat ${exportDir}/$currDocId/MANIFEST.MF | awk '{ if (NR > 1) print $0}'`
do
nextFileName=`echo $a | awk -F\; '{print $1}'`
nextDocId=`echo $a | awk -F\; '{print $2}'`
nextMD5Val=`echo $a | awk -F\; '{print $3}'`
echo " Downloading file ${nextFileName} with Document ID ${nextDocId} ..."
java -jar ${UCMRidcDir}/oracle.ucm.fa_client_11.1.1.jar DownloadTool \
--propertiesFile=${propFile} \
--log_file_name=/tmp/fileDownload_$$.txt \
--outputDir=${exportDir}/${currDocId} --md5 --md5lowercase \
--dID=$nextDocId --RevisionSelectionMethod Latest
downldMD5=`cat /tmp/fileDownload_$$.txt | grep MD5 | awk -F= '{print $2}' | awk -F\] '{print $1}'`
if [ $nextMD5Val != $downldMD5 ]
then
echo "Error: MD5 checksum value for downloaded file is incorrect!"
echo "Exiting!"
fi
done
echo "`date +%Y%m%d%H%M%S`" > ${exportDir}/${currDocId}/download.complete
echo " Done! Data Extract downloaded into directory ${exportDir}/${currDocId}!"
else
echo " Not downloading extract data into directory ${exportDir}/${currDocId} as previously downloaded on `cat ${exportDir}/${currDocId}/download.complete`"
fi
echo "-----------------------------------------------------------------------------------------"
echo ""
i=`expr $i + 1`
done
Check for file existence in UCM
The screenshot below shows the structure of a directory tree as it appears after downloading BICC data extraction files via script UCMTransferUtil.sh above. As stated above an indicator for a finished download is the existence of a text file called download.complete. This file contains the information of timestamp when download process for this BICC extraction run has been finished.
The search script will check run according to the following algorithm:
- run search of MANIFEST.MF files from starting directory – here named /export like shown in screenshot below and passed as parameter 1 to the script
- check if a file download.complete exists in every directory where a MANIFEST.MF file was found
- try to connect to UCM server with the connection information as existing in file passed as parameter 2 to the script
- if a successful connection could be established read all found MANIFEST.MF files in a loop
- determine all the UCM DocID’s and file names contained in each MANIFEST.MF file
- connect to UCM and search for the according document
- report the number of found documents (0 = none existing, 1 = doc exist)
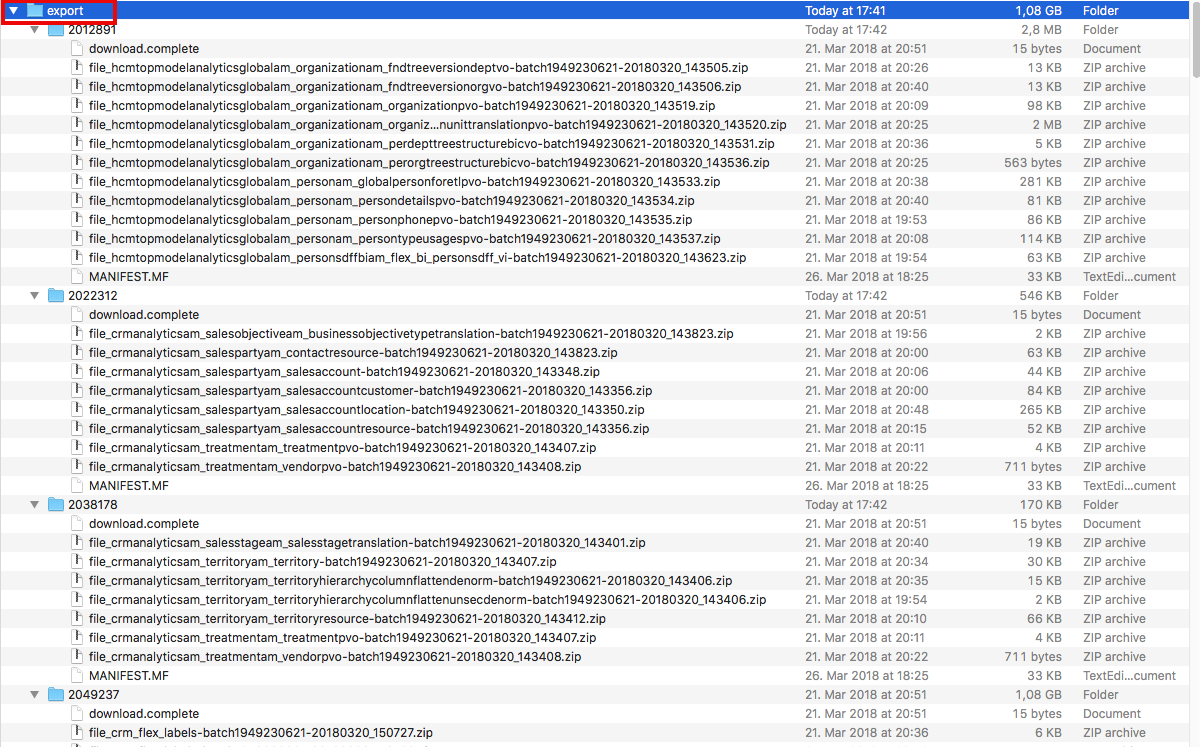
This search script called searchBICCFileUCM.sh takes two parameters:
- link to file with UCM connection properties (documented in Webcenter Document Transfer Utility docs)
- directory name as the starting point for searching MANIFEST.MF files
Before running this script one modification in code below must be performed in lines 23 and 24: Please change values for environment variables UCMToolDir and UCMRidcDir, according to your specific environment requirements.
#!/bin/bash
# Copyright (c) 2018 Oracle and/or its affiliates. All rights reserved
#
# ujanke: 2018/04/13 initial release
#
# This script searches for MANIFEST.MF files in a local folder. If a data extraction has been previously completely downloaded
# indicated by existence of a file named download.complete the content of every found MANIFEST.MF will be read and interpreted.
# Via the UCM DocID the script will check the existence of that document in UCM. It will report the number of files found in
# UCM - typically a 1 for an existing file or 0 for a non-existing document. Other numbers are not plausible as the UCM DocID is
# the primary key.
#
# This script uses the Webcenter Document Transfer Utility as existing here:
# http://www.oracle.com/technetwork/middleware/webcenter/content/downloads/wcc-11g-downloads-2734036.html
#
# IMPORTANT: Before running the script you have to change also the value for environment variables UCMToolDir and UCMRidcDir
# to cover your conditions. Both variables must be modified in lines 24 and 25 in script below!
#
# Two parameters are expected by this script:
# 1) link to file with UCM connection properties (documented in Webcenter Document Transfer Utility docs)
# 2) entry point for search script to look for MANIFEST.MF files
#
export UCMToolDir=/foo/bar/BICC/UCMTransferUtil
export UCMRidcDir=/foo/bar/BICC/UCMTransferUtil/ridc
if [ $# -lt 2 ]
then
echo "Wrong number of arguments!"
echo "Usage: $0 <UCM connection properties file> <starting directory>"
echo " <UCM connection properties file> : file with connection information to UCM by using the RIDC library"
echo " <starting directory> : starting point for recursive search of MANIFEST.MF files"
exit 1
else
propFile=$1
startingDir=$2
fi
java -jar ${UCMRidcDir}/oracle.ucm.fa_client_11.1.1.jar SearchTool --propertiesFile=${propFile} --ping --quiet --silent > /dev/null 2>&1
connSuccess=`echo $?`
if [ ${connSuccess} -ne 0 ]
then
echo "Error: Connection to UCM server failed! Please check your connection information in ${propFile}"
exit 1
fi
find ${startingDir} -name MANIFEST.MF -print > /tmp/$$.out 2>/tmp/$$.err
for manifestFile in `cat /tmp/$$.out`
do
manifestDocID=`dirname ${manifestFile} | awk -F/ '{print $NF}'`
manifestFileName=`echo ${manifestFile} | awk -F/ '{print $NF}'`
manifestDir=`dirname ${manifestFile}`
lineCount=0
if [ ! -f ${manifestDir}/download.complete ]
then
echo " WARNING: Can't determine UCM download completion as file ${manifestDir}/download.complete can't be found!"
echo " Skipping deletion in UCM for file ${manifestFile} ..."
else
echo "Checking existence of files in UCM for MANIFEST file ${manifestFile}:"
for docLine in `cat ${manifestFile}`
do
# first line in MANIFEST.MF is an internal information and we delete MANIFEST.MF itself in UCM at first element
if [ ${lineCount} -eq 0 ]
then
docID=${manifestDocID}
docName=${manifestFileName}
else
docID=`echo ${docLine} | awk -F\; '{printf("%d", $2)}'`
docName=`echo ${docLine} | awk -F\; '{printf("%s", $1)}'`
fi
java -jar ${UCMRidcDir}/oracle.ucm.fa_client_11.1.1.jar SearchTool \
--quiet --propertiesFile=${propFile} \
--dID=${docID} \
--delimiter=, \
--fields=dID,dDocName,dInDate,dOriginalName,VaultFileSize --defaultFields=false > /tmp/$$.search
rsCount=`cat /tmp/$$.search | awk '{if (NR == 3) print $0}' | awk '{print $1}'`
echo " ... ${rsCount} file ${docName} with UCM ID ${docID} existing"
lineCount=`expr ${lineCount} + 1`
done
fi
done
rm /tmp/$$.search /tmp/$$.err /tmp/$$.out 2>/dev/null
The output of this search script will look similar to screenshot below.

As explained above, if a directory has no existing files in UCM anymore it can be removed from an active export directory to avoid further search runs in future. If a minimum of one file is still existing (maybe caused from an incomplete previous deletion) the UCM files deletion program mentioned below could run again and again for this directory. It won’t touch any files locally or in UCM as not existent.
Delete BICC Data Extraction Files in UCM
Custom Java Program to delete files in UCM
Before running any document deletion in UCM we have to emphasize the importance of having a local backup of the extraction files as such a deletion can’t be undone. The deletion logic follows this algorithm:
- connect to UCM
- open the MANIFEST.MF file and process line by line
- ignore the first line in file as this contains release information
- reading of all other entries in Manifest file and parsing the fields separated by semicolon
- second field in line represents the UCM DocID as the primary key for a document containing extraction data
- Java program sends a deletion request for this file to UCM server via RIDC API
- If http request returns status 200 we can assume the deletion request was processed successfully
- Any other value will cause the program to stop

This Java program called DeleteBICCDocs runs on command line interface (CLI) and accepts three parameters:
- <UCM connection property file> – connection.properties from WebCenter Content Document Transfer Utility for RIDC library
containing URL, user name, password and policy to access Fusion SaaS UCM - <location for MANIFEST.MF> – Manifest File with the UCM Doc ID from a BICC data extraction run (absolute path to the file)
- <DocID for MANIFEST.MF> – UCM Doc ID for the MANIFEST.MF as this information is not available in the Manifest file itself
The Java program below uses the UCM API’s coming with RIDC library as being provided in file oracle.ucm.fa_client_11.1.1.jar. As mentioned before its published with the Webcenter Document Transfer Utility. You have to add this library to your CLASSPATH, before running the custom BICC Deletion of Data Extraction Files in UCM program below. If using the deletion shell script as shown further below these parameters are set by the script.
By using the Webcenter RIDC Java library, another dependency occurs: some classes of Apache Commons library must be added to the CLASSPATH after downloading from the Apache web site or according proxy servers:
- Apache commons-codec-1.11 Java Library as provided here: http://www-us.apache.org/dist/commons/codec/binaries/commons-codec-1.11-bin.zip
- Apache commons-httpclient-3.1 Java Library as provided here: http://www.apache.org/dist/httpcomponents/commons-httpclient/binary/commons-httpclient-3.1.zip
- Apache commons-logging-1.2 Java Library as provided here: http://www-us.apache.org/dist/commons/logging/binaries/commons-logging-1.2-bin.zip
In the beginning, the Java program validates the existence and readability of the UCM server connection file. Same for the connection properties and Manifest files. In a next step it will validate the connection information and count the lines in Manifest file (for reporting reasons).
As mentioned earlier in this article, the lines in Manifest file contain semicolon separated entries with the information about UCM files belonging to this specific extraction. The Java program determines UCM DocID as provided in the second entry. It constructs a service request for UCM to delete a document identified by its unique DocID. A Java code snippet is listed below. You can copy it, paste it into the IDE of your choice and have to edit some changes as indicated as comments below before you can compile it:
/* Java Code Snippet to delete BICC Data Extract Files in UCM
Copyright (c) 2018 Oracle and/or its affiliates. All rights reserved
Snippet created by Ulrich Janke, Oracle A-Team on 28-Mar-2018
Important: you have to modify the code before you can compile it! Its just a sample we're providing here!
Description :
- program takes three arguments
1) <UCM connection property file> - connection.properties from WebCenter Content Document Transfer Utility for RIDC library
containing URL, user name, password and policy to access Fusion SaaS UCM
2) <location for MANIFEST.MF> - Manifest File with the UCM Doc ID's from a BICC data extraction run (absolute path to the file)
3) <DocID for MANIFEST.MF> - UCM Doc ID for the MANIFEST.MF as this information is not available in the Manifest file itself
- after validation of readability of input files and checking UCM connection the program goes through all the entries in MANIFEST.MF
file and calls the UCM service to delete the data extraction file via its UCM Document ID
- MANIFEST.MF file will be deleted as the last one
Dependencies:
- UCM RIDC Java Library from WebCenter Content Document Transfer Utility oracle.ucm.fa_client_11.1.1.jar
- Apache commons-codec-1.11 Java Library http://www-us.apache.org/dist/commons/codec/binaries/commons-codec-1.11-bin.zip
- Apache commons-httpclient-3.1 Java Library http://www.apache.org/dist/httpcomponents/commons-httpclient/binary/commons-httpclient-3.1.zip
- Apache commons-logging-1.2 Java Library http://www-us.apache.org/dist/commons/logging/binaries/commons-logging-1.2-bin.zip
Known limitations:
- the RIDC service API doesn't return a statement whether the file has been deleted successfully or not
- the project code checks for the HTTP response code and will break the further execution if its not status 200
- HTTP-200 will be returned independently of the result that a file in UCM has been deleted or not
- means the program can run as often as possible and it will evert return HTTP-200 even if the file doesn't exist anymore in UCM
- it is recommended to check the status of a data extraction file's existence from outside this program vis the SearchTool included in
the WebCenter Content Document Transfer Utility
*/
package oracle.ucm.fa_client_11.custom;
/* Organize your imports! You need to import:
- java.io.File
- java.io.FileNotFoundException
- java.io.FileReader
- java.io.IOException
- java.util.Collection
- java.util.Iterator
- oracle.stellent.ridc.IdcClient
- oracle.stellent.ridc.IdcClientException
- oracle.stellent.ridc.IdcClientManager
- oracle.stellent.ridc.IdcContext
- oracle.stellent.ridc.model.DataBinder
- oracle.stellent.ridc.protocol.ServiceResponse
Don't forget to add the Apache libraries and RIDC library from Webcenter Document Transfer Utility to you CLASSPATH */
class DeleteBICCDocs
{
public DeleteBICCDocs()
{
super();
}
public static void main(String[] argv) throws IOException
{
String[] errMsg;
if( argv.length != 3 )
{
errMsg = new String [] {"Error: Incorrect number of parameters!"};
printErrorUsage(errMsg);
return;
}
char [] connInfo, manifestInfo;
IdcContext idcContext;
FileReader connFileReader, manifestFileReader;
File connFile, manifestFile;
String manifestDocID, connFileName, manifestFileName;
connFileName = argv[0];
manifestFileName = argv[1];
connFile= new File(argv[0]);
manifestFile = new File( argv[1]);
manifestDocID = new String(argv[2]);
for (char c : manifestDocID.toCharArray())
{
if(! Character.isDigit(c))
{
errMsg = new String [] {"Error: Argument >" + manifestDocID + "< must contain numbers only!"};
printErrorUsage(errMsg);
return;
}
}
if( ! checkFile(connFile, connFileName))
return;
if( ! checkFile(manifestFile, manifestFileName))
return;
try
{
connFileReader = new FileReader(connFile);
manifestFileReader = new FileReader(manifestFile);
connInfo = new char[(int) connFile.length()];
manifestInfo = new char[(int) manifestFile.length()];
connFileReader.read(connInfo);
manifestFileReader.read(manifestInfo);
}
catch( FileNotFoundException fnfe )
{
System.err.print("Exception: FileNotFound");
System.err.print(fnfe.getMessage());
return;
}
catch( IOException ioe )
{
System.err.print("Exception: IOException");
System.err.print(ioe.getMessage());
return;
}
System.out.print("Running DeleteBICCDocs ...");
System.out.print(" Deleting files as contained in file >" + argv[1] + "< ...");
String[] connDetails = getConnDetails(connInfo);
System.out.print(" UCM URL is >" + connDetails[0] + "< and user name is >" + connDetails[1] + "< ...");
String[] docInfo = getDeletionInfo(manifestInfo);
System.out.print(" File >" + manifestFileName + "< contains >" + (docInfo.length) + "< files to delete in UCM ...");
try
{
System.out.print(" Connect to " + connDetails[0] + " ...");
idcContext = doConnect(connDetails);
}
catch(IdcClientException ice)
{
System.out.print("Exception: IdcClientException when creating an UCM connection!");
System.err.print(ice.getMessage());
return;
}
if( ! doDeleteDocs(idcContext, docInfo, connDetails[0], manifestDocID))
{
System.err.print(" <<< Deletion of docs in UCM failed!!! >>>");
System.out.print("UCM file deletion aborted");
}
else
{
System.out.print(" Docs deletion in UCM finished!");
System.out.print("UCM file deletion successfully finished!");
}
// ... add any other Exception handlers as necessary
return;
}
// parse the connection.properties file (values passed as a char[]) for the connection information
// this handling of the connection details is a standard feature of the Webcenter Document Transfer Utility
private static String[] getConnDetails(char[] connInfo)
{
String fullInfo, userName, passWord, ucmURL, policy;
String[] infoArr;
String[] retArr = new String[4];
ucmURL = "url";
userName = "username";
passWord = "password";
policy = "policy";
fullInfo = new String(connInfo);
infoArr = fullInfo.split("\n");
for( String connLine : infoArr )
{
String[] matchLine = connLine.split("=");
// zero element is the URL
if( matchLine[0].equalsIgnoreCase(ucmURL))
retArr[0] = matchLine[1];
// first element is the user name
if( matchLine[0].equalsIgnoreCase(userName))
retArr[1] = matchLine[1];
// second element is the password
if( matchLine[0].equalsIgnoreCase(passWord))
retArr[2] = matchLine[1];
// third element is the policy
if( matchLine[0].equalsIgnoreCase(policy))
retArr[3] = matchLine[1];
}
return retArr;
}
protected static void printErrorUsage( String[] msgArr )
{
for (String msgArr1 : msgArr)
{
System.out.print(msgArr1);
}
System.out.print("Usage: DeleteBICCDocs <UCM connection property file> <location for MANIFEST.MF> <DocID for MANIFEST.MF>");
}
protected static IdcContext doConnect(String[] connDetails) throws IdcClientException
{
IdcContext idcContext;
idcContext = new IdcContext(connDetails[1], connDetails[2]);
return idcContext;
}
protected static Boolean doDeleteDocs(IdcContext idcContext, String[] docInfoArr, String url, String manifestDocID)
{
IdcClient idcClient;
IdcClientManager clientManager;
DataBinder binder;
int numUCMFiles = docInfoArr.length;
String[] docsToDelete = new String[numUCMFiles +1];
int i, n = 0;
for(i = 0; i < numUCMFiles; i++)
docsToDelete[i] = docInfoArr[i];
docsToDelete[numUCMFiles] = "MANIFEST.MF;" + manifestDocID + ";";
try
{
clientManager = new IdcClientManager();
idcClient = clientManager.createClient(url);
idcClient.initialize();
binder = idcClient.createBinder();
String ucmFileName;
String ucmDocID;
ServiceResponse ucmResponse;
for( String docLine : docsToDelete )
{
if(n >= 1)
{
String[] matchLine = docLine.split(";");
// zero element is the file name
ucmFileName = matchLine[0];
// first element is the UCM Doc ID
ucmDocID = matchLine[1];
System.out.print(" ... deleting file >" + ucmFileName + "< with UCM DocID >" + ucmDocID + "< from UCM");
binder.putLocal("IdcService", "DELETE_DOC");
binder.putLocal("dID", ucmDocID);
ucmResponse = idcClient.sendRequest(idcContext, binder);
Collection<String> headerNames = ucmResponse.getHeaderNames();
Iterator<String> headNameIt = headerNames.iterator();
String headValue;
String[] valueDetails;
// check the HTTP Header of response
while( headNameIt.hasNext())
{
headValue = ucmResponse.getHeader(headNameIt.next());
valueDetails = headValue.split(" ");
// if the header name contains HTTP/1.1 we look for the status
if( valueDetails[0].equalsIgnoreCase("HTTP/1.1"))
{
// if status is not 200 we break the program here
if( ! valueDetails[1].equalsIgnoreCase("200"))
{
System.out.print(" ... ----> Issue with HTTP request status, return value expected = 200, status returned = " + valueDetails[1]);
System.out.print("Aborting!!!");
return false;
}
}
}
}
n++;
}
}
// add all appropriate exception handlers as necessary - one sample is posted below
catch(IdcClientException ice)
{
System.out.print("Error: IdcClientException in doDeleteDoc");
System.out.print(" " + (n - 2) + " of " + numUCMFiles + " files deleted in UCM!");
System.err.print(ice.getMessage());
return false;
}
System.out.print(" " + (n - 1) + " deletion requests sent to UCM!");
return true;
}
private static String[] getDeletionInfo(char[] manifestInfo)
{
String fileInfoArr;
String[] docArr;
fileInfoArr = new String(manifestInfo);
docArr = fileInfoArr.split("\n");
return docArr;
}
private static boolean checkFile(File fileObj, String fileName)
{
String[] errMsg;
if(! fileObj.isFile())
{
errMsg = new String [] {"Error: File >" + fileName + "< is not a file!"};
printErrorUsage(errMsg);
return false;
}
if(! fileObj.canRead())
{
errMsg = new String [] {"Error: File >" + fileName + "< is not readable!"};
printErrorUsage(errMsg);
return false;
}
if(fileObj.length() == 0)
{
errMsg = new String [] {"Error: File >" + fileName + "< is empty!"};
printErrorUsage(errMsg);
return false;
}
return true;
}
}
Important: as long as no connection error occurs, the return status from UCM deletion request will be HTTP-200. Independently whether the file could be found, deleted, not found or not deleted. This is not an optimal situation but couldn’t be implemented easily without massive addition of code to check the status via RIDC API. During my own testing, the files were deleted successfully or the deletion request did also return no error message if the file didn’t exist. I intended to focus strictly on the deletion part and did not implement any additional routines to check the file existence before or after the deletion request at this time. For those status checks, the shell script searchBICCFileUCM.sh as listed above should be executed again. It will report the number of files (0 or 1) for all dedicated UCM DocID’s.
Shell Script for deleting files in UCM recursively
For an automated periodical deletion process does it make sense to create a wrapper script called deleteBICCDocsUCM.sh around the Java program described above. The sample below shows a shell script that will accept two parameters
- the link to an UCM connection properties file by providing the absolute path
- the starting point for a recursive search for Manifest files
All other conditions for the local existence of the Apache Commons libraries must be fulfilled. Before running the script, it has to be edited by changing the values for environment variables UCMToolDir (pointing to the directory with the Java file and Webcenter RIDC library) and ApacheLibDir (pointing to directory containing the Apache Commons JAR files as needed by RIDC library).
Before running this script one modification in code below must be performed in lines 30, 31 and 33: Please change values for environment variables UCMToolDir, ApacheLibDir and ucmRidcDir according to your specific environment requirements.
#!/bin/bash
# Copyright (c) 2018 Oracle and/or its affiliates. All rights reserved
#
# ujanke: 2018/04/13 initial release
#
# This script searches for MANIFEST.MF files in a local folder. If a data extraction has been previously completely downloaded
# indicated by existence of a file named download.complete the content of every found MANIFEST.MF will be read and interpreted.
# Via the UCM DocID for every file listed in MANIFEST.MF the script will delete that document in UCM.
# The Webcenter Document Transfer Utility API doesn't unfortunately recognize the status of a UCM file deletion. As long as the
# HTTP status is 200 the custom Java program will assume the deletion was performed correctly. To determine the successful
# deletion of files in UCM please run the search shell script afterwards to see if the files still exist or have been deleted.
#
# This script uses the RIDC Java API of Webcenter Document Transfer Utility as existing here:
# http://www.oracle.com/technetwork/middleware/webcenter/content/downloads/wcc-11g-downloads-2734036.html
# Furthermore this API requires three Apache Commonons libraries as being available for download on Apache.org website:
# 1) http://www.apache.org/dist/httpcomponents/commons-httpclient/binary/commons-httpclient-3.1.zip
# 2) http://www.apache.org/dist/commons/codec/binaries/commons-codec-1.11-bin.zip
# 3) http://www.apache.org/dist/commons/logging/binaries/commons-logging-1.2-bin.zip
#
# IMPORTANT: After download you have to extract these files into a local folder of your choice and assign the environment variable
# ApacheLibDir to this folder as the location becomes part of the CLASSPATH.
# Before running the script you have to change also the value for environment variables UCMToolDir and ucmRIDCDir to cover your conditions.
# Both variables must be modified in lines 35 and 36 in script below!
#
# Two parameters are expected by this script:
# 1) link to file with UCM connection properties (documented in Webcenter Document Transfer Utility docs)
# 2) entry point for search script to look for MANIFEST.MF files
#
export UCMToolDir=/foo/bar/BICC/UCMTransferUtil
export ApacheLibDir=${UCMToolDir}/Apache/lib
export CLASSPATH=${ApacheLibDir}/commons-codec-1.11.jar:${ApacheLibDir}/commons-httpclient-3.1.jar:${ApacheLibDir}/commons-logging-1.2.jar:${UCMToolDir}/lib/oracle.ucm.fa_client_11.custom.jar:${UCMToolDir}/ridc/oracle.ucm.fa_client_11.1.1.jar
export ucmRIDCDir=/foo/bar/BICC/UCMTransferUtil/ridc
if [ $# -lt 2 ]
then
echo "Wrong number of arguments!"
echo "Usage: $0 <UCM connection properties file> <starting directory>"
echo " <UCM connection properties file> : file with connection information to UCM by using the RIDC library"
echo " <starting directory> : starting point for recursive search of MANIFEST.MF files"
exit 1
else
propFile=$1
startingDir=$2
fi
java -jar ${ucmRIDCDir}/oracle.ucm.fa_client_11.1.1.jar SearchTool --propertiesFile=${propFile} --ping --quiet --silent > /dev/null 2>&1
connSuccess=`echo $?`
if [ ${connSuccess} -ne 0 ]
then
echo "Error: Connection to UCM server failed! Please check your connection information in ${propFile}"
exit 1
fi
find $startingDir -name MANIFEST.MF -print > /tmp/$$.out 2>/tmp/$$.err
for manifestFile in `cat /tmp/$$.out`
do
manifestDir=`dirname $manifestFile`
echo "Found MANIFEST file ${manifestFile} ..."
if [ ! -f $manifestDir/download.complete ]
then
echo " WARNING: Can't determine UCM download completion as file ${manifestDir}/download.complete doesn't exist!"
echo " Skipping deletion in UCM for file MANIFEST.MF in path ${manifestDir}"
else
echo "... invoking UCM deletion program ..."
manifestDocID=`echo ${manifestDir} | awk -F/ '{print $NF}'`
java oracle.ucm.fa_client_11.custom.DeleteBICCDocs ${propFile} ${manifestFile} ${manifestDocID}
fi
echo "------------------"
echo ""
done
rm /tmp/$$.out /tmp/$$.err 2>/dev/null
This script will perform a find operation for files with name MANIFEST.MF recursively from starting directory. For all files being found it will invoke the Java program oracle.ucm.fa_client_11.custom.DeleteBICCDocs as explained further up in this blog and pass the required parameter:
- 1. Absolute path of connection properties file
- 2. Absolute path of Manifest file
- 3. UCM DocID of Manifest file
The third parameter of UCM DocID will be determined from the directory name of the Manifest file if downloaded before by script UCMTransferUtil.sh. As explained above this directory has been created with the DocID as the name. Unfortunately, this is the only choice to refer to the UCM DocID for Manifest file as the file itself doesn’t contain that information.
By setting the starting point via the second parameter for shell script above, we control the scope of the deletion process. Screenshot below shows the scope for just one directory if we parameter will be set to path /scratch/BICC/export/2097867. All other directories under /scratch/BICC/export will be out of scope and no deletion will be performed for the files belonging to dedicated Manifest files in those directories.
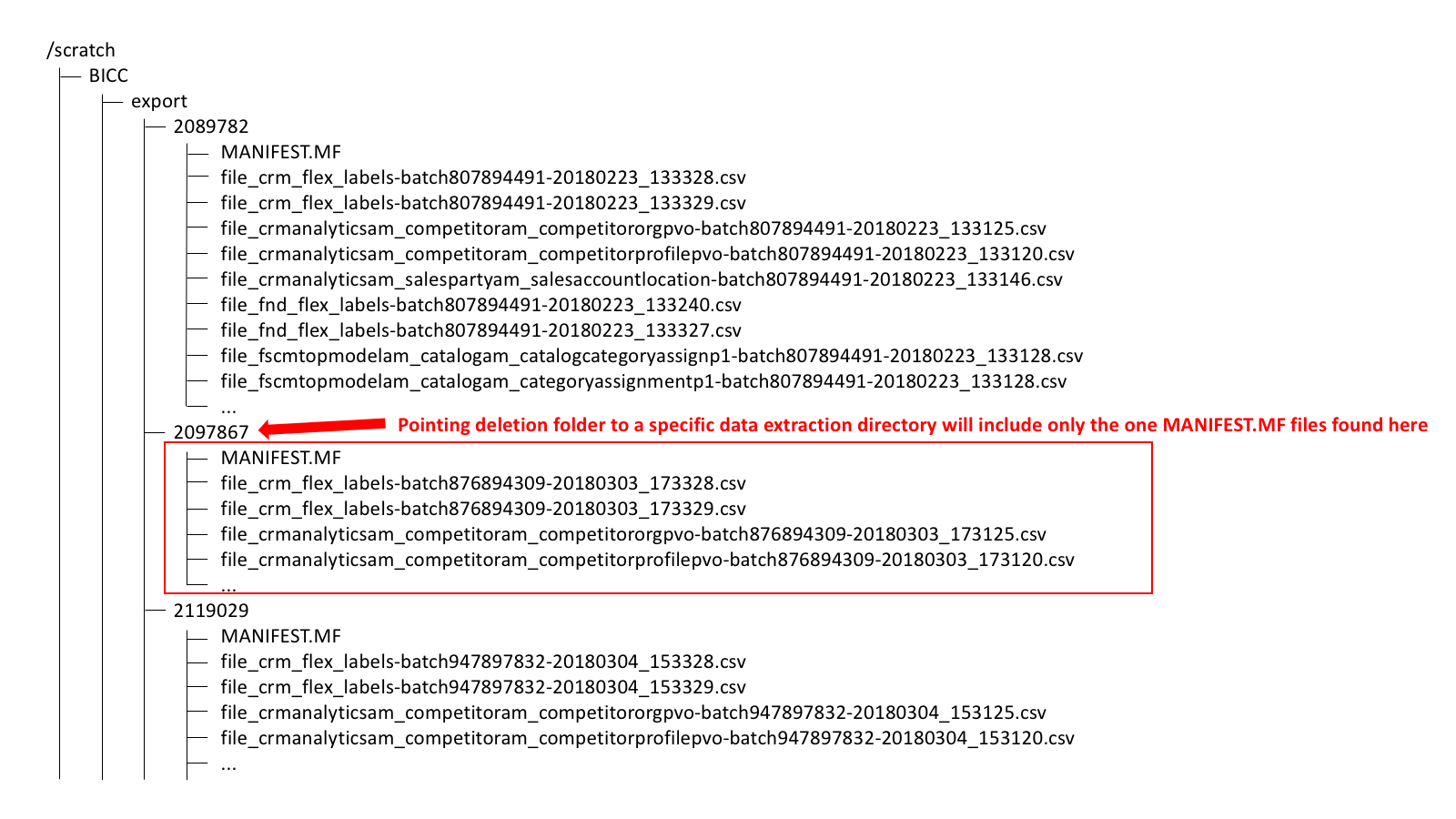
In contradiction, by setting the path to /scratch/BICC/export, all subdirectories will be in scope and deletion in UCM will happen for all files listed in each of the Manifest files being found.

By running this script, the output will look like shown in screenshot below. This sample shows the recursive search of MANIFEST.MF files and the output produced by the script. As mentioned above: the Java deletion program will handle all files via their UCM DocID’s as listed in Manifest file and attempt to delete them. These files will be reported in standard output without any status information whether the deletion was successful or not (reason explained in description of functionality for Java program above).

To justify the success of UCM document deletion you must check the existence by running the search script again. Once all files were reported with zero occurrence, the subdirectory should have taken out of scope for any subsequent deletion runs.
Conclusion
This post handled the topic about file deletion in UCM for BICC after introducing the downloading capabilities in former blog BI Cloud Connector Download of Data Extraction Files. Storage Cloud based downloads can be reached via NFS and tidying up those extracts is more straight forward than in UCM. That required a special explanation of a data extract removal strategy for the UCM based option.
To summarize the take-aways for an end-to-end BICC data extraction strategy please consider these steps if the process is intended to run fully automated:
- Configure UCM as a storage location of data extracts in BICC
- Define the scope for data extraction and schedule a periodical process in BICC
- Setup a cron job on a local Linux server to download and unzip the data extraction files via script UCMTransferUtil.sh
- Setup the automated loader processed into Data Warehouses, Data Lakes or local Databases as required
- Setup another cron job on the Linux server to backup the ZIP files into local archives once loaded
- Perform the following tasks to tidy up the UCM folders from BICC data extract documents
- Run the deletion script deleteBICCDocsUCM.sh as introduced above and set the scope to the extraction directory – the script will run the Java program oracle.ucm.fa_client_11.custom.DeleteBICCDocs as provided above
- Run the search script searchBICCFileUCM.sh afterwards to validate the success of deletion process in UCM
- Review the search results and rerun deletion if required
- Take the processed directories out of scope by removing them from the extraction directory
Important to mention that the download script UCMTransferUtil.sh is not capable to compute the required disk space in advance. It is under the responsibility of the system administrator to ensure sufficient disk space exists. Otherwise the entire download process will break with an exception.