On the topic of fault handling in Integration Cloud (IC), there are three types of Fault Actions that can be leveraged: 1. Re-throw Fault, 2. Throw New Fault, and 3. Fault Return. More times than not, a discussion comes up around why faults thrown in IC are always HTTP 500. This is not necessarily true and this blog will clarify the behaviors of each of the Fault Actions. To illustrate the Fault behaviors, a simple integration will be used where URI Parameters control the various scenarios.
Example Integration – Fault Action Behavior Example
This integration is setup to throw/return faults at a scoped level and at the Global Fault level. There are default handlers in the scope and Global Fault that will demonstrate what happens when the three types of Fault Actions are used. To control the flow/scenarios, the following three URI Parameters are used:
faultType – throw-new, rethrow, return
faultScope – scoped or global
httpCode – Any code to surface in the fault
The faultScope parameter is used in the main flow of the integration to either branch into a scope or throw a new fault that will be caught by the Global Fault handler:
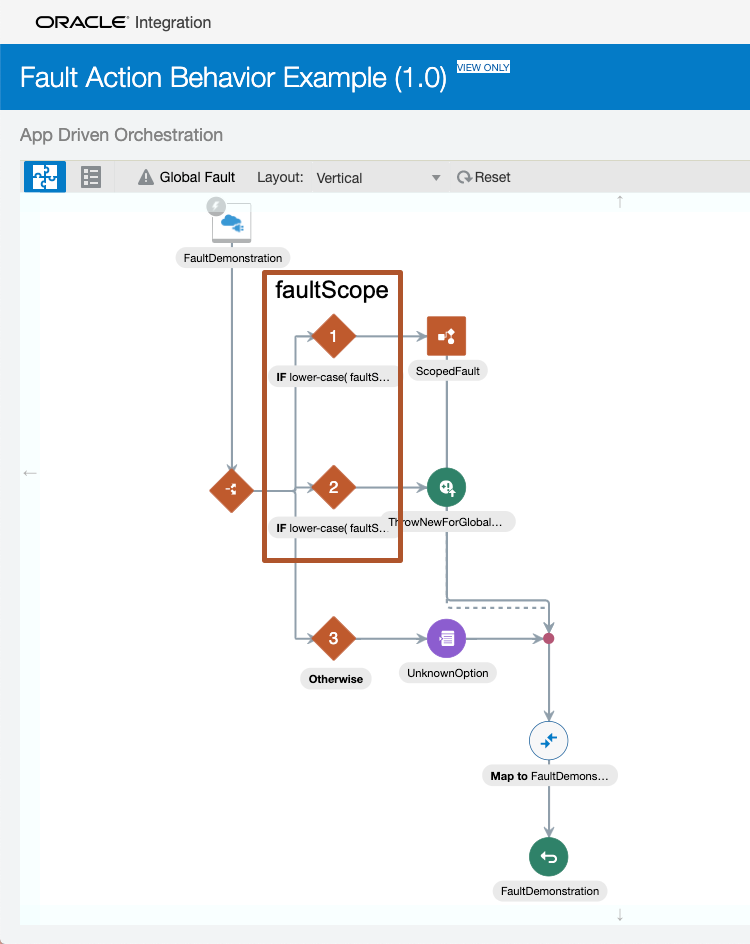
Once we are in either the Default Handler for the scope or the Global Default Handler, the faultType parameter is used to control what Fault Action will come into play:
Default Handler for Scope

Global Fault Handler

NOTE: To force the flow into the scope Default Handler, a new fault is thrown in the scope.
Now we can use the integrated IC Test client to drive the various scenarios:

Scoped
Throw New

Re-throw

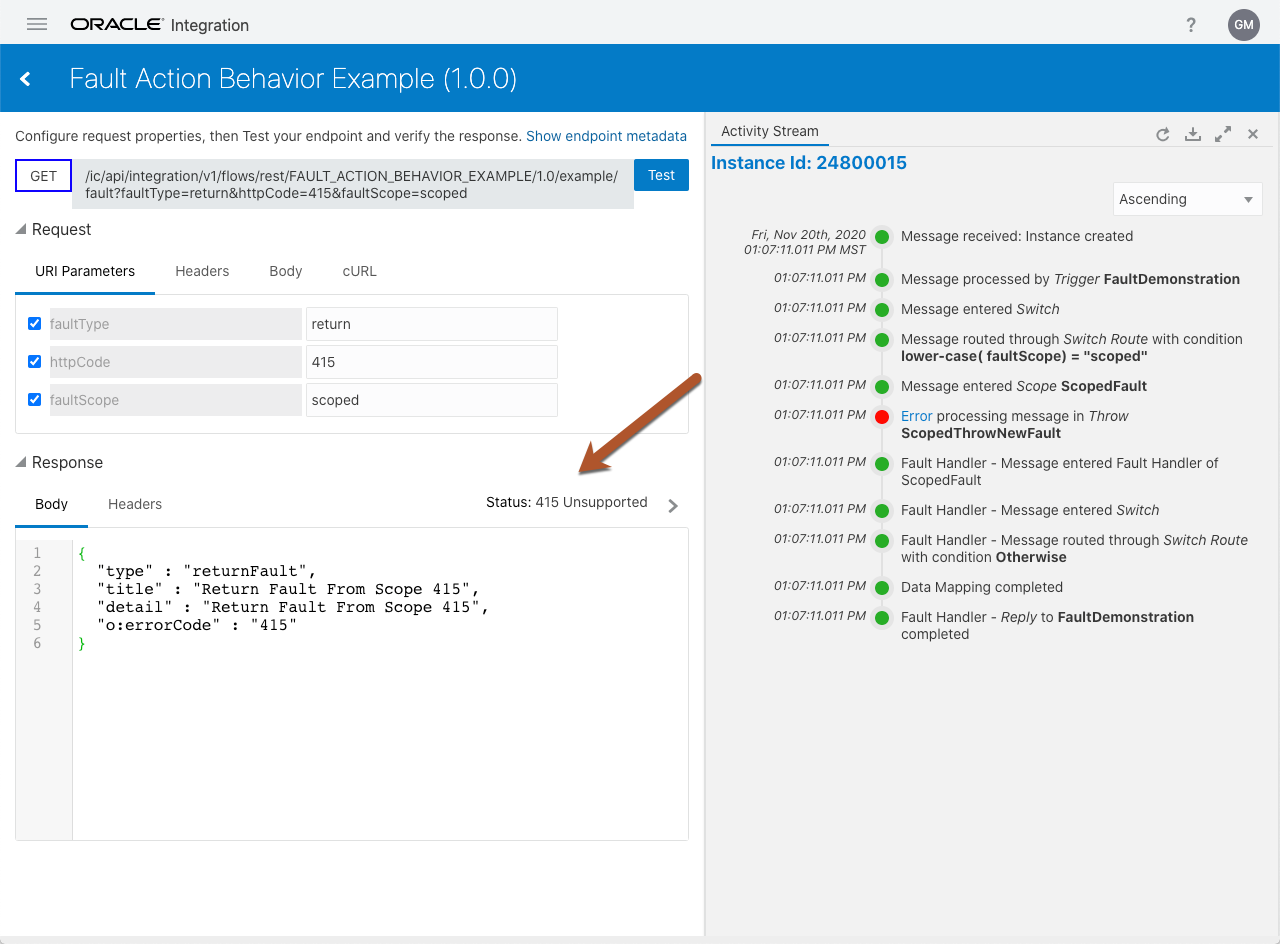
Return Fault
Global
Throw New

Re-throw

Return Fault

Observations
We can see that whenever a fault is “thrown” (throw-new or rethrow), IC will surface the fault as a 500 Internal Server Error with the real fault in the “o:errorDetails”. The biggest complaint with this behavior is the actual errorCode is buried in the “o:errorDetails”. Adding to the challenge, what if the business use case requires that the actual HTTP status code be surfaced vs. a generic 500 status code? Based on our test cases, we have an option with the Return Fault Action as the correct HTTP status code is returned along with the fault details. However, this has a not so obvious impact on the integration instance Status:

Notice that the instance Status for the Return Fault Action results in Succeeded vs. Errored. What this means is the error in the integration has been caught and handled successfully resulting in a status being returned to the caller. On the flip side, when the integration throws a fault it means that the integration instance did not successfully handle the fault and is throwing it to the caller to take care of it.
NOTE: This may be obvious to some, but it’s worth pointing out that Return Fault Action is only available in synchronous integrations. With asynchronous flows there is no caller to return a fault to ¯\_(ツ)_/¯
Hopefully this gives you a better feeling on what approach will be best for your integration development.
Happy Integrating!!!
