Introduction
A load balancer (LB) monitors the health of the backend servers periodically to ensure that the requests are served only by healthy servers in a backend set. The OCI LB service supports 2 approaches for checking the health of the backend servers:
TCP – Checks if a TCP (Layer 4) connection can be made to the backend server on a specified port.
HTTP – Checks if a pre-configured URI is accessible over HTTP (Layer 7) and returns the expected result ( Status code or response data pattern).
If your backend servers have an HTTP interface, you should ideally avoid using TCP health checks. However, if your backend servers are databases (DB) like MySQL or PostgreSQL, using TCP health checks becomes the only choice as the databases don’t provide an HTTP interface.
So, why consider going beyond TCP health checks?
TCP health checks are preliminary, hence not very reliable as they can produce false positives. For example, when the backend server is merely up but not allowing any new DB connections or is very slow and not returning results to the queries. In short, the DB is up but not healthy, these checks still report the health of the server as OK. With TCP checks, the load balancer will send requests to the backend servers that are possibly unhealthy resulting in a broken failover strategy.
A simple solution to avoid these false positives is to set up an HTTP health check that runs alongside your backend service and executes granular checks. It returns an HTTP 200 response if a backend server’s status is good or an error code like HTTP 503 to indicate that something is wrong. I’ll explain this solution with some sample code snippets that can be used with any non-HTTP backend service ,like databases, to make health checks more accurate and reliable.
Below is a depiction of two Node MySQL/PostgreSQL DB servers front-ended with OCI LB. The load balancer distributes DB traffic over TCP on the database listener ports ( 3306 for MySQL or 5432 for PostgreSQL) and health checks are done over HTTP on the health check service port.
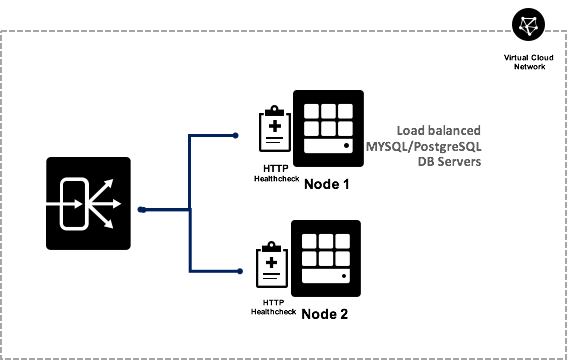
I created an HTTP health check as shown in the diagram using Python 3. This pattern can also be created using any language of your choice. The health check script runs on every node of the backend service. For example, if you have three backend servers in your load balancer backend set then the health check script should run on all three of those servers.
My HTTP health check script is explained below,
Step 1 – Read all the variables from a configuration file.
config.read(file_name, 'UTF-8')
dbname = config.get(db_section, 'Name')
username = config.get(db_section, 'Username')
password = config.get(db_section, 'Password')
dbtype = config.get(db_section, 'Type')
query = config.get(db_section, 'Query')
host = config.get(server_section, 'IP')
port = config.get(server_section, 'Port')
Load the required DB modules
if dbtype == 'mysql':
import mysql.connector
elif dbtype == 'postgresql':
import psycopg2
Step 2 – Run your script as an HTTP server
server = HTTPServer((host, port), RequestHandler)
server.serve_forever()
Step 3 – Connect to MySQL or PostGreSQL
if dbtype == 'mysql'
try :
mydb =mysql.connector.connect(
host="localhost",
user=username,
passwd=password,
database=dbname )
elif dbtype == 'postgresql'
try :
mydb = psycopg2.connect(
database=dbname,
user=username,
password=password,
host="localhost" )
Step 4 – Run a query of your choice to ensure that the DB is running.
This would typically be a select query that tells your DB schema is operating as expected.
try:
if mydb :
dbcur = mydb.cursor()
dbcur.execute(query)
response_code = 200
response_text = "OK"
except Exception as e :
print("Error running the query ".format(e))
finally:
if dbcur: dbcur.close()
if mydb: mydb.close()
If the DB connection is successful and the query executes successfully, return HTTP 200. If not, return an error code like HTTP 503.
self.send_response(response_code)
self.send_header("Content-Type", "text/html")
self.end_headers()
self.wfile.write(bytes(response_text, "utf-8"))
Step 5 – Integrate with systemd.
Assuming you run your DB servers on a Unix system, integrate the health check service with systemd. This is an optional step but it is strongly recommended to configure autostart for health check service either after a system reboot or a process restart. The primary component of systemd is a “system and service manager” – an init system used to bootstrap user space and manage user processes.
Below is a sample .service file for the health check service :
[Unit]
Description=Health Check Service
[Service]
User=opc
WorkingDirectory=/home/opc/health_check/
#I created a simple shell script to point to activate my python3 virtual environment
# and invoke the python script with configuration file argument
ExecStart=/home/opc/health_check/healthcheck.sh
# Restart the process when it fails.
Restart=always
RestartSec=10
[Install]
WantedBy=multi-user.target
Step 6 – Allow traffic from the LB to your health check service port
a. Update the security list attached to the backend server’s subnet to allow traffic from the LB CIDR to the healthcheck listener port.
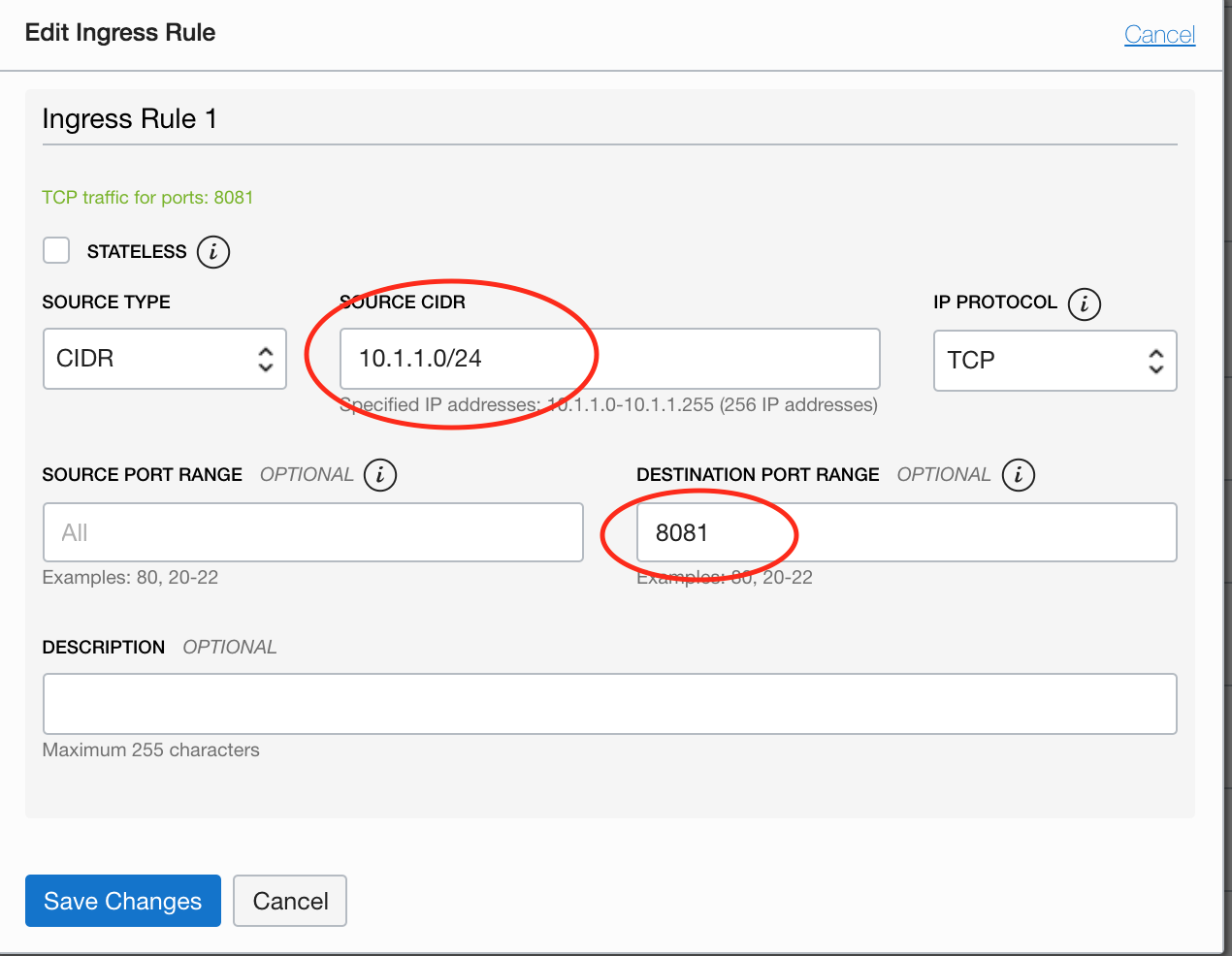
b. Update the firewall settings on each of your backend servers to allow traffic on the listener port.
Example shows Oracle Linux firewall-cmd :
sudo firewall-cmd --zone=public --add-rich-rule 'rule family=ipv4 source address=10.1.1.0/24 port port=8081 protocol=tcp accept' --permanent ;
Step 7 – Update the load balancer health check policy to point to your health check service
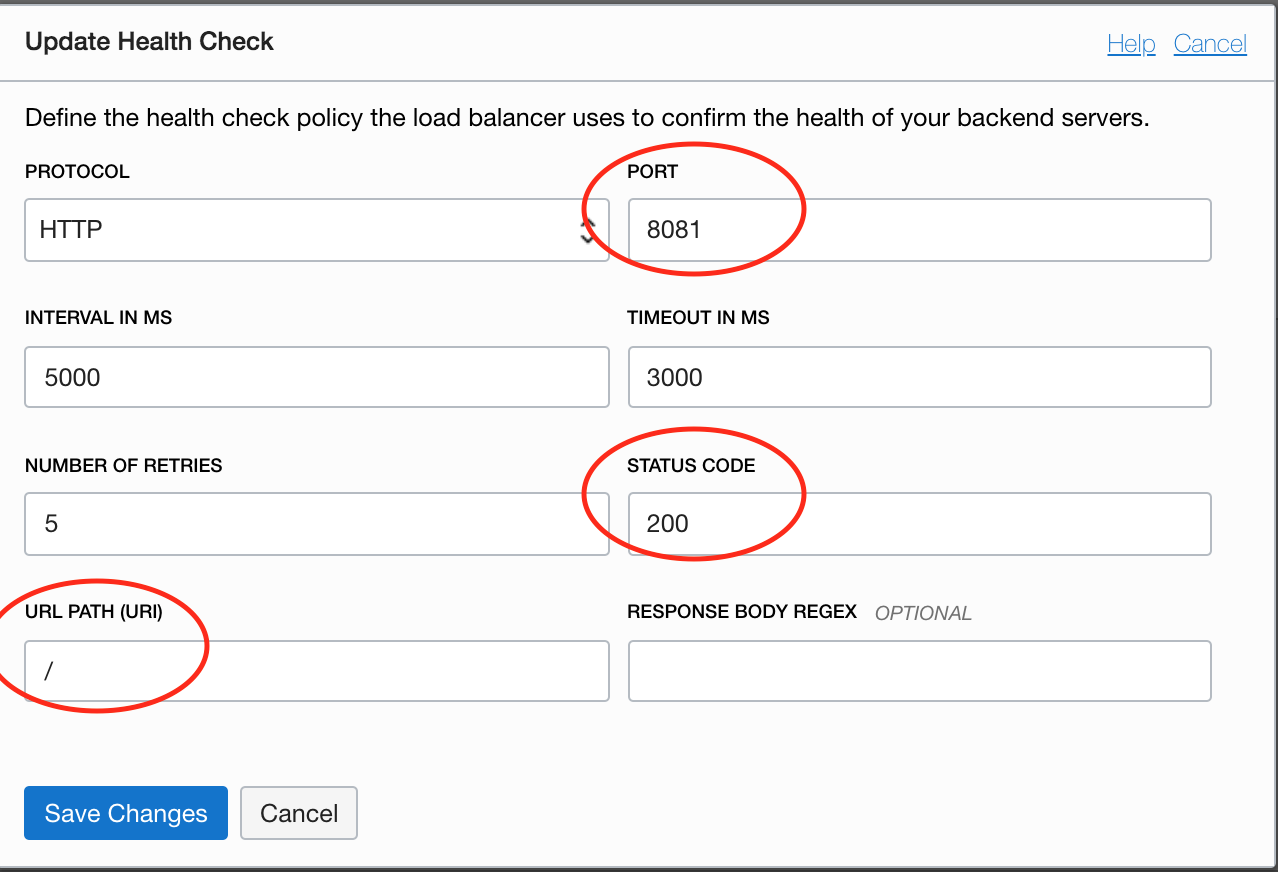
After this step, the server state in LB should reflect the health status as OK assuming your DB server is up and running.
Summary
TCP health checks are not reliable. If a backend server already supports an HTTP interface, one should leverage that option and not setup TCP health checks. If the backend is not an HTTP service, adding a simple HTTP interface provides a more reliable and accurate health check of your service making the failover more robust.
