Parsing product descriptions with Oracle Enterprise Data Quality
This blog is a continuation of a series on product data management using Oracle Enterprise Data Quality (EDQ).
It covers description parsing to extract and enhance attributes on the fly, and starts with a recap of category parsing from the first article.
Category Classification with parsing
The first job we need to perform on product descriptions is to classify each row into its primary category. If we can identify a row as being for some variant of screw, for example, then we narrow down the steps required to identify and extract all of attributes which apply to screws, without having to worry about looking for any attributes which would apply to a motor.
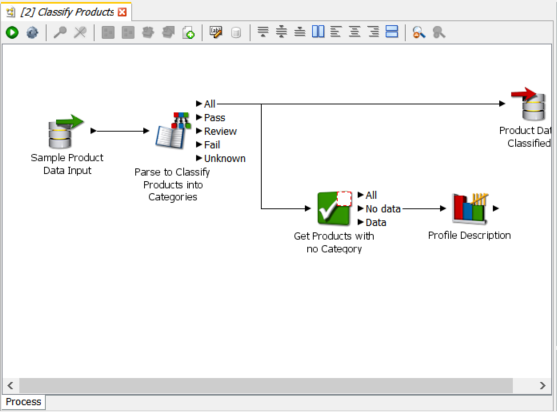
The reader in this process reads the exact same two column data as the reader in the previous blog. At the top right we have a new processor type, the Writer, which writes data out to the staged data stores within the EDQ repository. If we look at the data in the Writer we will see that we have an additional column:
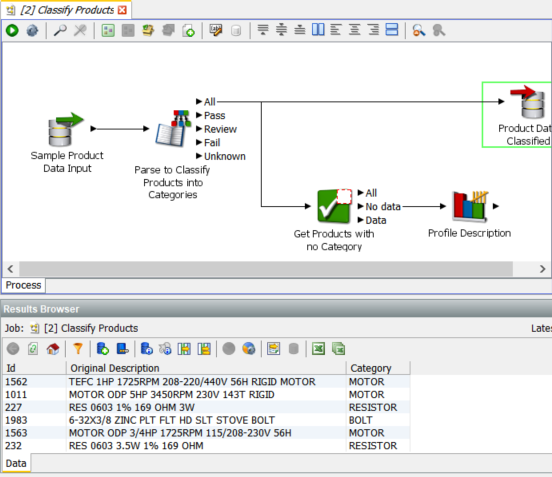
The Category column has been filled with a category value derived from the data in ‘Original Description’. This data has been derived by the Parse process which is one of the most powerful processors in EDQ:
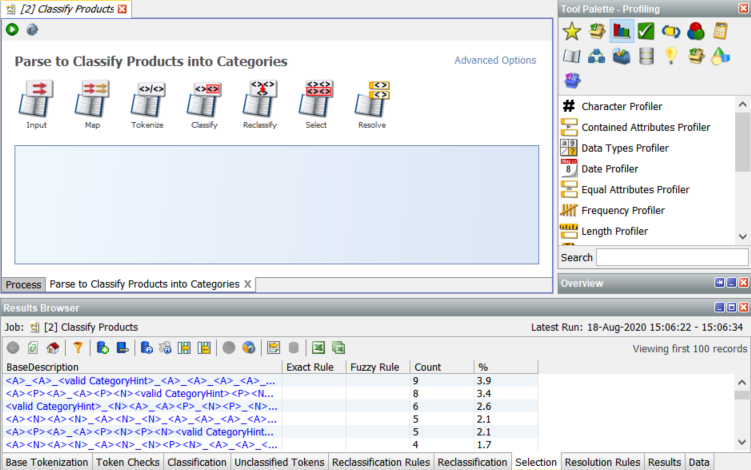
The Parser has 7 dialogs which control its configuration. For the purposes of this document we will only look at the Classify dialog:
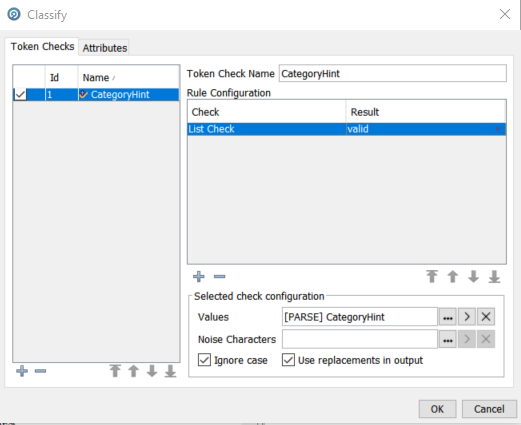
This configuration says that we will perform a list check using the individual tokens in the ‘Product Description’ column and that will use the values in the resource table ‘[PARSE] CategoryHint’. Note the checkbox ‘Use replacements in output’ – this will result in the derived ‘Category’ being output. The ‘[PARSE] CategoryHint’ contains the following:
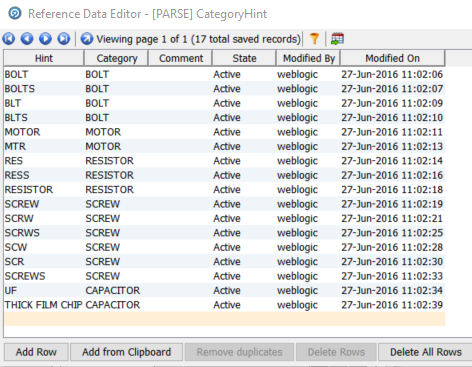
You can see here that we have multiple synonyms for bolts, motors, resistors, screws and capacitors which will be replaced by the value in the Category column in the reference data. If the processor find a token equal to ‘SCREW’, ‘SCRW’, ‘SCRWS’, ‘SCW’, ‘SCR’ or ‘SCREWS’ then it will assign the row to the ‘SCREW’ category. EDQ ships with sets of pre-prepared reference data, and the reference data can be extended with data from the Phase Profiler and can also be created from scratch, either with the EDQ Director interface or in e.g. Excel which can later be inserted or imported into reference data.
Extracting Dimensions
In this section we will go through a more sophisticated analysis of the ‘Product Description’ column and extract the dimensions of the screws in the data. This section is performed as a walkthrough adding to an incomplete process:
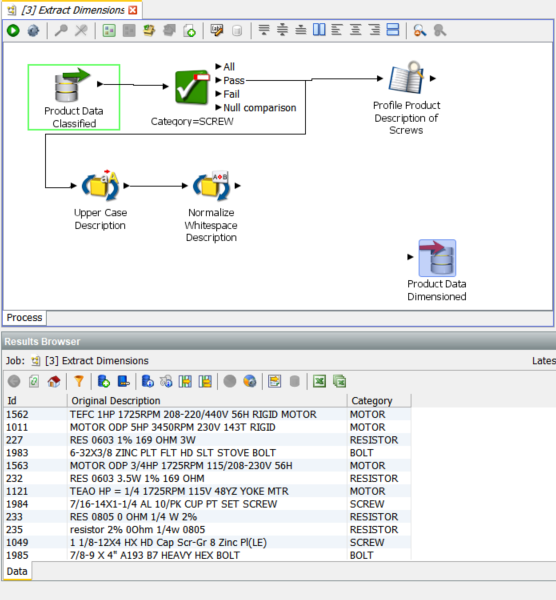
We have now changed the reader definition and are using the output from the previous process with the added ‘Category’ column.
The next processor is a simple value check to split the data into the ‘SCREW’ category and to ignore everything else. The configuration of the value check is:
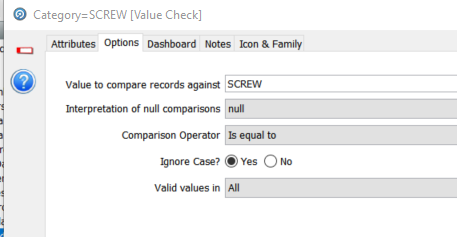
Each value in ‘Category’ is compared to the value ‘SCREW’. If true then the row is passed on. If not then it is, in this case, ignored.
The first processor is a Phrase Processor which we originally saw in the basic profiling section. The configuration of this instance is richer, in particular for multi token phrases:
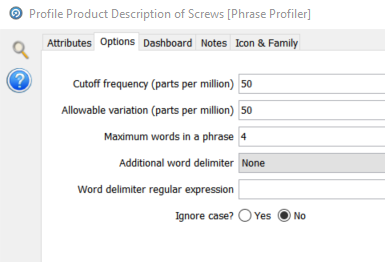
The maximum words in a phrase is now set to 4. This means that any continuous set of one to four tokens will be included in the frequency count:

We now get multi token phrases like ‘SET SCREW’, ‘HEAD CAP SCREW’ and ‘Flat Head Zinc Plated’
The ‘SCREW’ data stream is also forked to the processor ‘Upper Case Description’ followed by ‘Normalize Whitespace Description’. These are simple standardisations, the former changes the case of all letters to upper case and the latter removes spaces from the beginning of strings and compresses all multiple space sequences into single spaces.
Parsing attributes
We are now going to take the output from the Extract Attribute processes and use the EDQ Parser to perform the identification of attributes and their values. In many cases only one of these methods will be needed for a given category (or categories) of product data.
The Parse processor supports rich attribute extraction and classification including the use of regular expressions, while Extract Attributes supports the use of literal values. However, we have combined the two approaches here to highlight the flexibility of EDQ, and in order to show that multi-step processing is often the best way to ensure no ambiguities when extracting data. The Parse processor can also standardize literal values as it extracts them, which is useful for our data since we know it contains some values that require this.
The process is superficially simple comprising 5 processors, including the reader and the writer and a simple column rename. We are primarily interested in the Parse processor. However, there is a Replace All processor prior to the Parser called Standardize Abbreviations. This uses the following replacement Reference Data table:
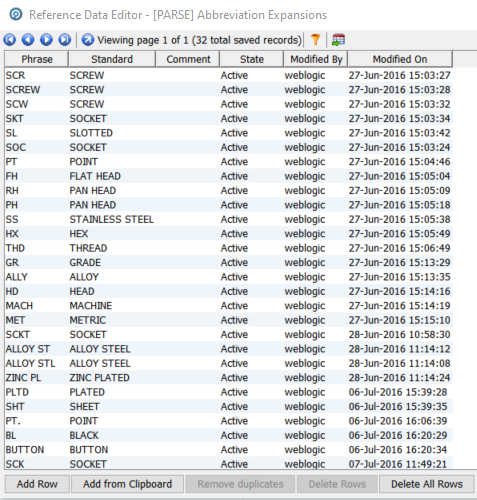
We could use the same resource in the Parser. However, in that case the standardisation would not be done before the other classifications are performed in the Parser. We are therefore performing this standardisation before the Parser. The results look like:
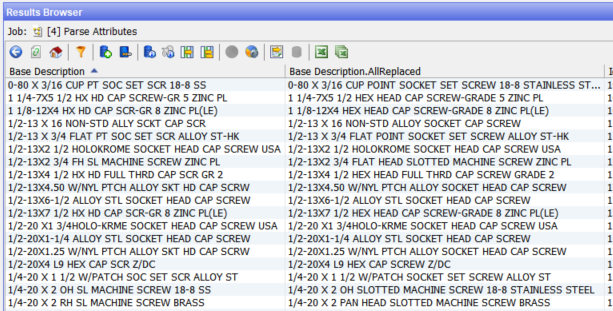
Once we have the description contents standardised we can proceed to the Parser:
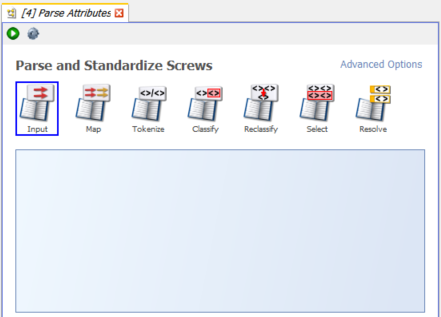
As stated before, there are 7 configuration stages for the parser.
Input dialog
The fist, Input, allows you to choose how many columns of data you are going to take through the Parser. We are taking them all so we will not look at this in detail.
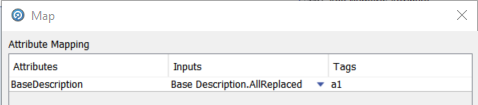
Map dialog
The next configuration step is Map which allows us to choose and rename the input column that will be operated on by the Parser:
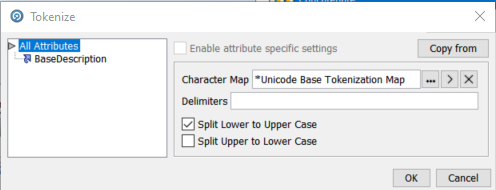
Tokenize dialog
The next configuration step is Tokenize which gives granular control of how we divide the tokens up within the field contents. In this case we are use the standard default Unicode Base Tokenisation Map to identify whitespace and control characters which will mark token boundaries and also to specify to Split on lowercase to uppercase transitions:
Classify dialog
The bulk of the work in this example is done by the Classify section:
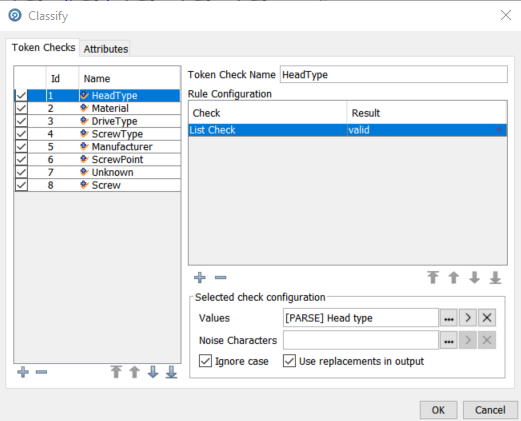
Token checks include List checks, Regular Expression checks, Attribute Completion, Character Length, Word Length and Base Token checks. The first two are the most common and all of the Token Checks in this example are list checks. The list is specified in the Selected check configuration panel Values field, [PARSE] Head type:
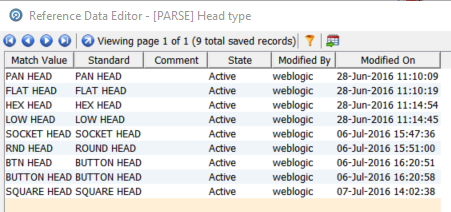
We have also checked Ignore case and also Use replacements in output which will ensure that RND will be standardised to ROUND and BTN to BUTTON in the output.
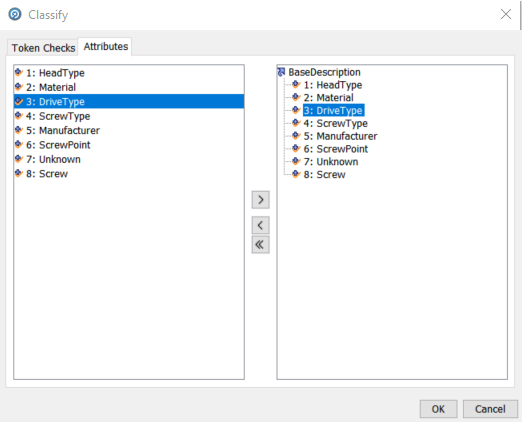
Unlike the standardisation done using the Replace All processor where all of the modifications were done to the original contents, the Parser creates a new attribute for each of the Token Checks. These are shown in the Attributes tab of the Classify dialog:
When the process is run 4 tabs are populated detailing the results:
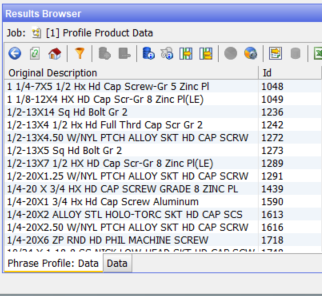
The Token Checks results show how many valid matches were found. Possible matches are primarily generated by the Regular Expression check type. Any blue field can be drilled into, for example the 4 <ScrewPoint> values are:

We can then drill in to the FLAT POINT rows:

where we can see the attribute values in the Base Description.AllReplaced column.
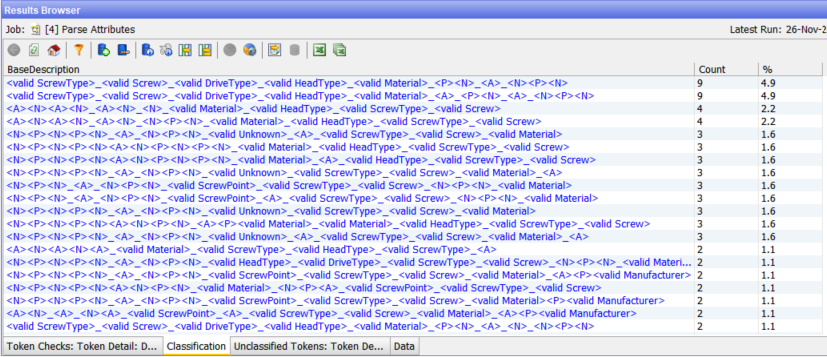
The Classification tab gives us a view of the patterns and frequencies of classifications.
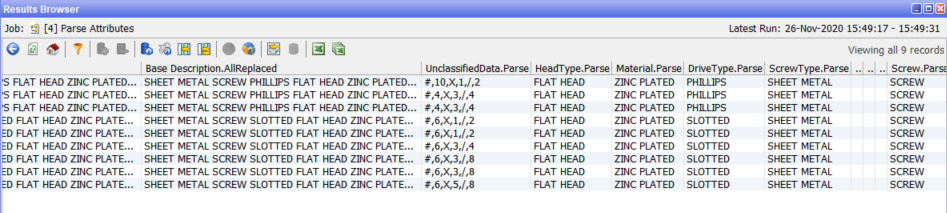
If we drill into the first row we see that valid attributes have been found for HeadType, Material, DriveType, ScrewType and Screw, each of which is now in an attribute of the same name with Parse appended:
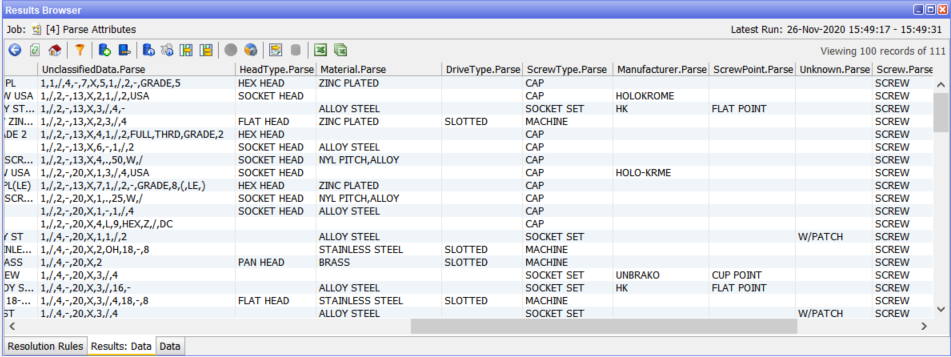
The Unclassified Tokens tab shows any token which did not match a check. This should be reviewed regularly to identify drift in the input.
Reclassify dialog
Reclassify covers the specification of rules to manipulate the basic tokens, including in sequence, to generate new tokens which can include parts of the original tokens. It is not used in this example.
Select dialog
The select dialog allows the application of frequency samples and range scoring to select which values are passed through to the next stage.
Resolve dialog
Resolve allows rules based assignment of classification patterns to particular output fields. This is useful in, for example, address or full name parsing. In this case we are using a simpler assignation technique in the Outputs tab:

We have checked the Automatic Extraction which will populate the named attributes to be populated in the Parser Output with the values found in the Classify phase.
This is shown in the Results: Data tab in the Resolve Results Browser:
Write out the data
This is simpler in this case as we just have to write out the additional columns as well as the original input column:
Summary
This walk through illustrates an alternative approach to identifying attributes and extracting their values.