Introduction
This blog will discuss various options available to integration developers for error handling using Oracle Integration Cloud (OIC). This blog does not aim to substitute the documentation, but aims to act as a ready reckoner when questions arise regarding OIC Error handling.
The OIC official doumentation has more details on some of these topics and should be used as the final reference. Refer here – OIC Documentation
Broadly, we will look at the below categories of error handling
- OOTB Error Handling – where we use the features of OIC to achieve error handling
- Extending error handling – where we use additional components like DBaaS to implement more complex use cases
Out Of The Box Error Handling
What are fault handlers?
Fault handlers are sections of integration flow that we want to execute in response to faults. Typically, fault handlers are not executed in the happy path scenarios ! These come into play only when invocations within integration flows encounter errors.
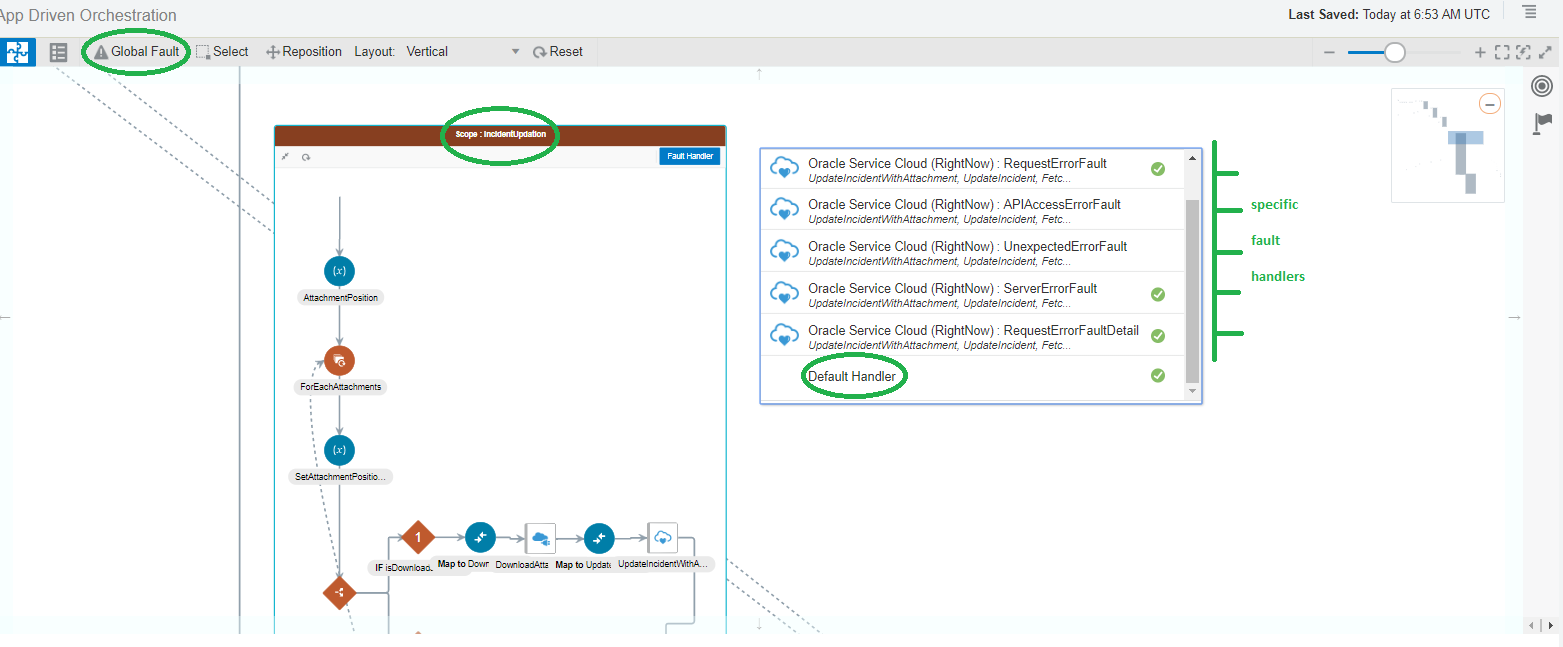
Fault Handlers – at scope level and global level
Fault Handlers are provided at the scope level to handle errors that arise during invoke actions within those scopes. Any named faults defined in the invoke actions within the scope, will generate separate fault handlers. Specific fault handling implementation can be added in these fault handlers.
In addition a Default Handler is also generated for every scope which acts as a catch-all block for that scope. Any error that is not handled by one of the specific fault handlers will be handled by the default handler. The default handler can be used to implement generic fault handling for that scope.
In addition to scope level fault handlers, there is a Global Fault Handler that is available at the overall integration flow level which acts as a super catch block. Any errors un-handled at the inner scopes or errors encountered in non scope blocks bubble up to this Global fault handler.
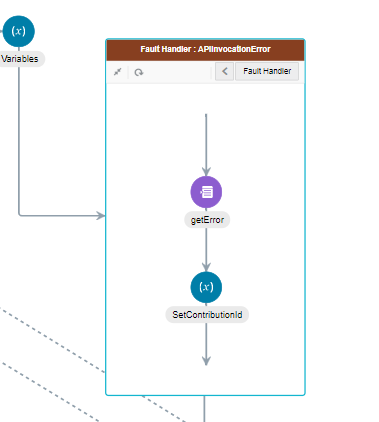
Picture below shows where you can find the various fault handlers within an orchestration flow.
Note that all these constructs are only available in orchestration type of integrations and will be absent in a Basic Routing type of flow.
All generic fault handling logic, common to the entire flow should be implemented here. The implementations are of course use case specific. An example implementations is to configure email notification to an admin user, who may be responsible for resubmitting any failed instances.
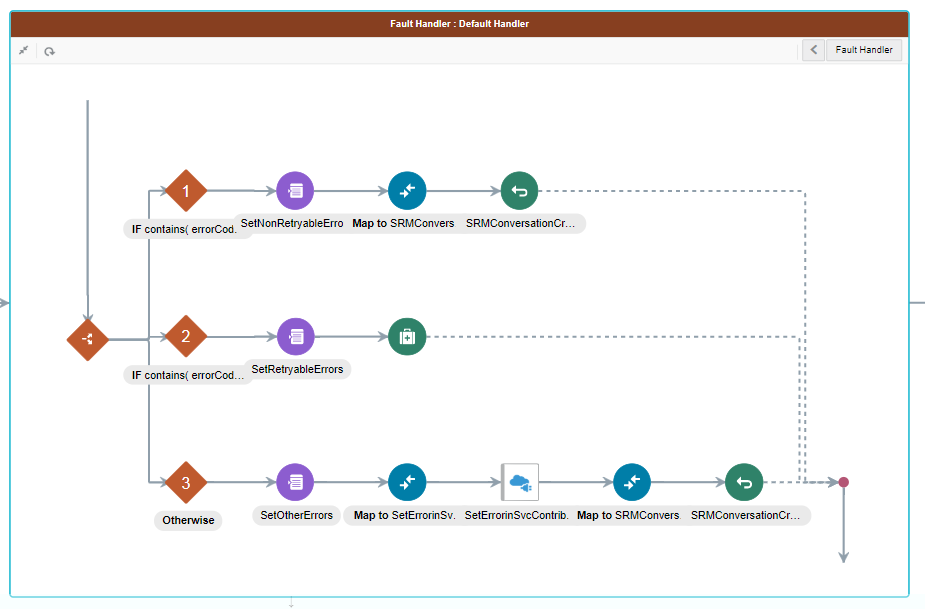
Picture below shows an example fault handler and various allowed actions that can be used within the handlers.
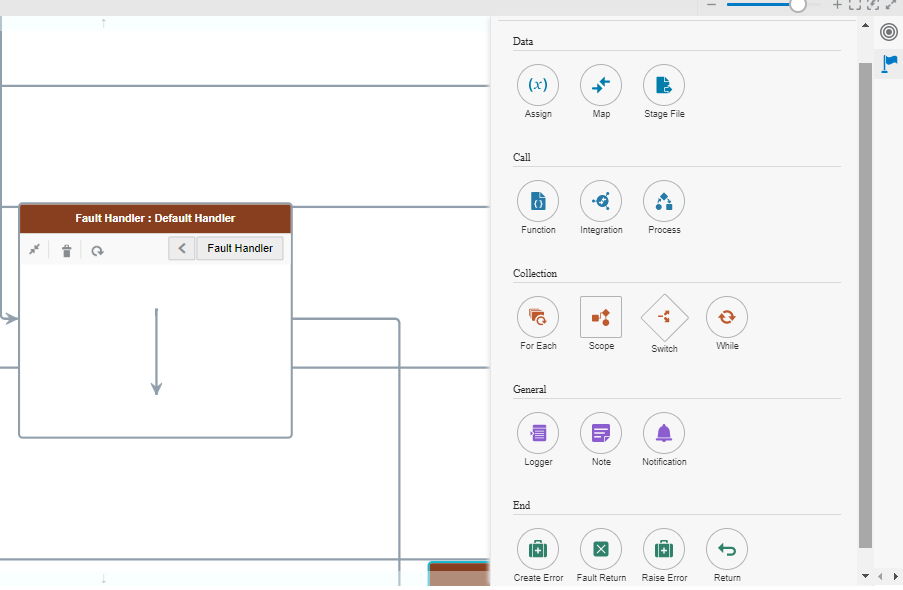
What can be implemented in these fault handlers?
Here are some of the common implementations in fault handlers. The corresponding pictures give an idea of what actions are used to achieve them.
- Bubble up the fault and terminate flow
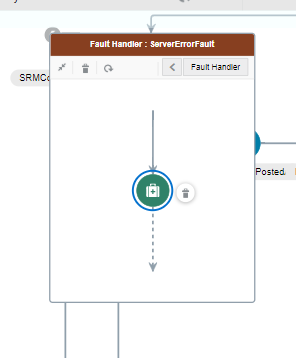
- Reply to caller with an error response
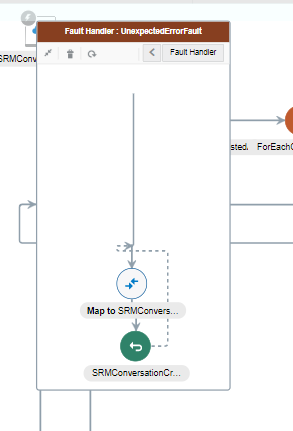
- Log the error and continue with the flow
- Assign for later aggregation and move on
- Check for various possible error codes and conditionally perform actions
 A few other examples are
A few other examples are
- Invoke a downstream endpoint to notify it of errors
- Append the error to a local stage file for aggregation
- Locally invoke a process flow in PCS
- this may initiate a workflow involving manual intervention for exceptional flow
The ‘Raise Error‘ (Error Hospital) and ‘Create Error‘ actions in the error handler implementation will bubble the error up and result in the flow instance being marked as faulted. Such instances can be seen in monitoring console as faulted instances.
Note – We will discuss about the ‘Create Error‘ action in a section below
Fault handler implementation that does not bubble up the error, is considered to have handled the error gracefully. Such instances will be marked as successful!
Nested Scopes
A word about nested scopes. Fault Handlers can be configured at nested scopes as well. The deeper scopes propagate the error to outer scopes when they bubble up the errors.
One could even have nested scopes with a scope’s fault handlers !
However, it is recommended to keep error handling as simple as possible. If the complexity within a fault handler is seen to be growing rapidly, it is time to consider having a separate integration flow to handle the fault handling logic and call it from the parent flow.
Create Error – Raise faults from your integration
We saw in scope level and global fault handlers, the ability to ‘handle’ faults that arise in invocations. What about usecases where an integration has a need to raise a custom fault even before it invokes downstream applications or even to avoid hitting the downstream applications ?
Now, OIC also provides the ability to Create a custom error and Raise it using the “Create Error” activity. This comes in handy when developers want to programatically raise errors based on certain criteria that the integration can evaluate. It is also useful to map a bunch of system errors to
more business friendly errors. For example, to convert a database “record unavailable error” to a “User is not registered, please signup here” error !
Picture below shows a Create Error in a flow
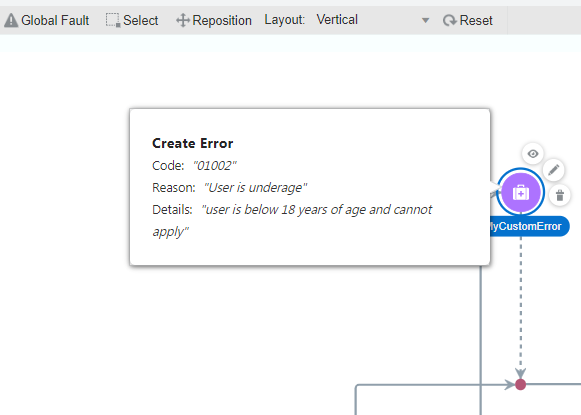
This feature is now Generally Available as “Throw New Fault action”
- OIC Whats new entry for Throw new Fault
- Refer to Engineering blog on this new feature here.
Resubmit failed instances
What happens to all the failed instances ?
Synchronous flow instances, when they fail throw the error back to the caller.
It is then the responsibility of the calling application or client to handle the error. Typically, clients can re-initiate the requests to OIC in case of failed synchronous flows.
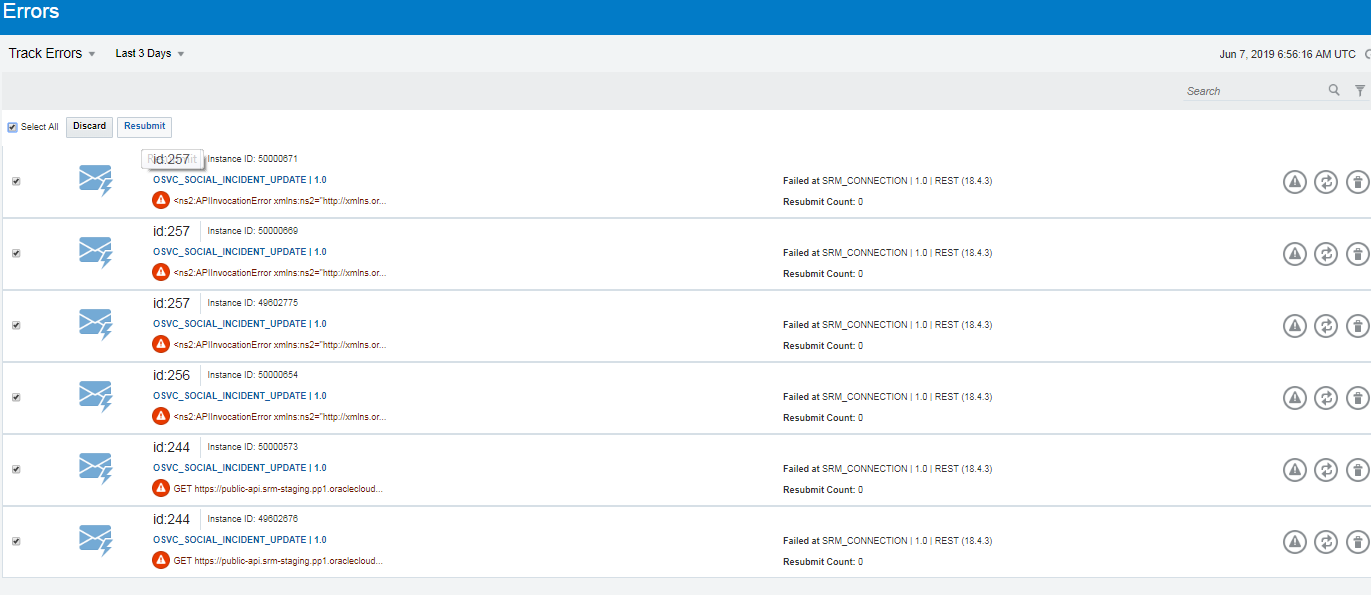
The OIC Monitoring console will show failed flow instances at the Errors page (OIC console –> Monitoring–> Errors )
Synchronous flow instances when seen from OIC monitoring will not show the “resubmit” or “discard” actions.
On the other hand, asynchronous flow instances can be resubmitted in the event of failure. Such faulted instances are available for resubmit during the retention period in OIC,
They can be selected from OIC monitoring console errors page (or other views as well. These can either be discarded or resubmitted.
Note that discarded flows cannot be retrieved further. Do not discard a message that you want to resubmit.
Picture below lists both types of faulted instances with the available actions
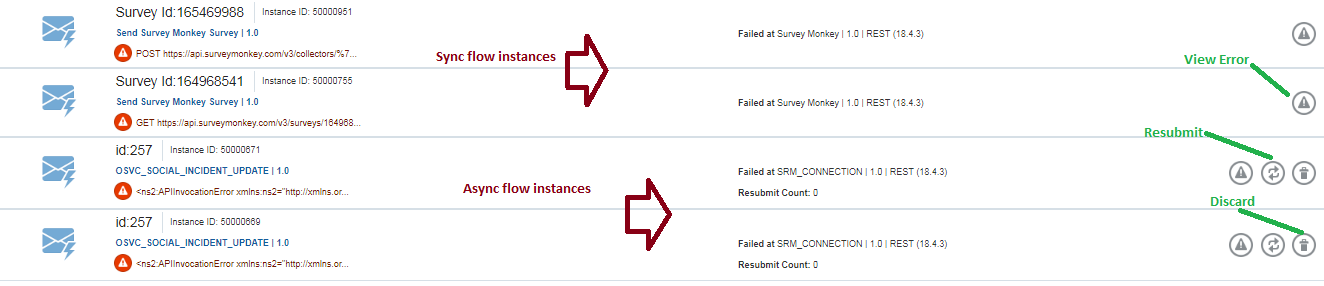
A flow instance can be selected and resubmitted from this monitoring view. Note that when an instance is resubmitted, it will start execution from the beginning of the flow.
Care should be taken while designing asynchronous flows to ensure that activities in the flow are repeatable without side effects (idempotent)
For example, if there is a need for an DB insert activity within the flow, ensure that duplicate records are not created on the DB.
One way to achieve this is by wrapping DB insert activity in a scope, and let a scope level error handler to gracefully handle the “DB Unique Constraint Violated” Error.
We have seen in above sections, how such error handlers can be implemented !
Bulk Resubmit
Extending Error Handling
In most use cases, it is possible to model integration flows as a series of safely repeatable steps. Such flows can take full advantage of the inbuilt error handling and monitoring features that we have seen in the above sections.
However, there may be few use cases where there is need for custom error handling, which require additional components for maintaining instance state and persisting the messages.
Some such use case examples are as follows –
- Use case requires that on re-submission, the flow retries from the last point of failure
- The completed tasks are not repeatable or require expensive compensation to make them repeatable
- The faulted instances are required beyond OIC retention period for re-submission
- There is need for changing the payloads when resubmitting the faulted instance
Parking lot pattern using database
This solution uses the popular Parking Lot pattern as basis to implement error handling enable re-submissions from point of failure. The original parking lot pattern is discussed here.
This extended error handling design involves the use of a database table for state tracking and storing metadata relating to the payload that is processed. In its simplest form, it can be implemented using a parking lot table or stage table in DBCS and 2 OIC integration flows, as shown in the below picture.
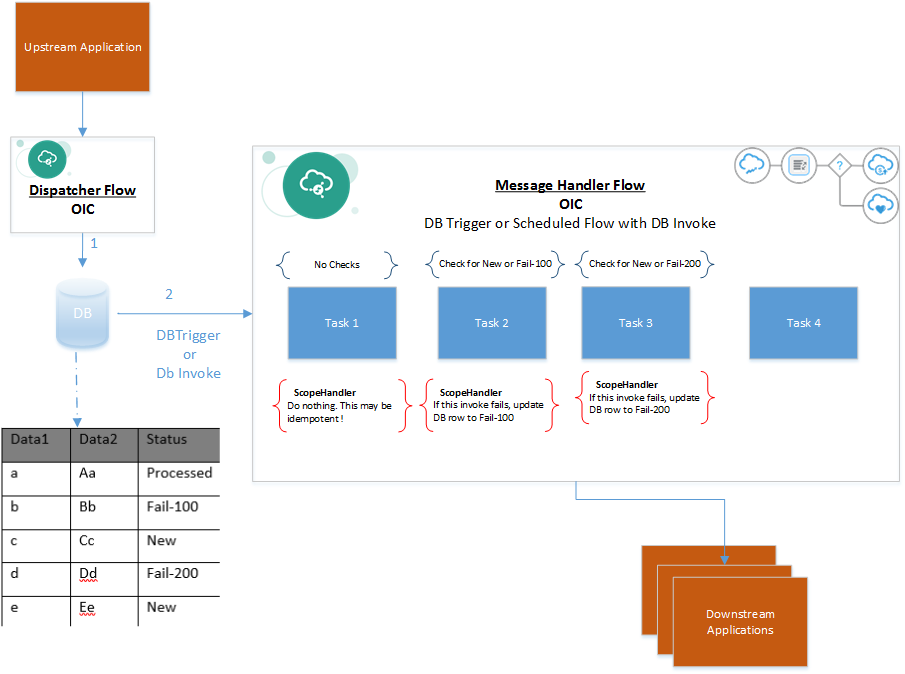
Note: The picture depicts a database generically. It could be backed by different database implementations based on the use case. If the integration’s center of gravity is onPrem, then the database could be an onPrem database instance. On the cloud, one could use the Oracle Cloud Infrastructure (OCI) – database system DBCS. It could also be an Autonomous database such as Autonomous Transaction processing (ATP) instance on OCI or the Visual Builder Cloud Service’s (VBCS) Business Objects database. The choice is architecture and use case specific.
Dispatcher
The Dispatcher OIC integration is responsible to receive messages to be processed from upstream source systems and persisting them into to a DBaaS stage table as new records. The stage table is designed to hold the input messages and their state of processing.
Message Handler
A Message Handler integration periodically polls the stage table and retrieves unprocessed input messages. Any errors during various stages of processing are ‘caught’ in scope level. Error handlers and the milestone stage is updated in the stage table. The subsequent polls of the message handler flow will retrieve these semi processed records and process them based on the appropriate milestone markers
Best Practices for the stage table and agent
- Delete or archive processed records to ensuring the table volume does not keep growing
- This is best done by scheduling a purge procedure for the table.
- Alternatively, the message handler flow can delete the message from the stage table after all the stages are completed processing.
- Create indexes on the stage table based on the select queries used for retrieving.
- This ensures optimal performance for the message handler flow in events of high volume.
- When DB Adapter used with DBCS, a connectivity agent is needed (not shown in picture above). Highly available (HA) agents can be installed to eliminate any single point of failure. Refer here for Agent HA.
- Note – ATP database does not need a connectivity agent !
Check out my new blog for more discussion on this popular pattern –
Advanced Error handling and Scheduling Best Practices – Oracle Integration Cloud
Error handling for file based integrations
Let us look at another design suitable for file based flows. Bulk interfaces using files often use an FTP server for file storage, This pattern will implement a simple error handling leveraging the FTP server and enable re-processing of failed instances by using multiple FTP folders and move operations between folders using FTP adapter.
An FTP server is used to receive input files containing multiple records to be processed downstream.
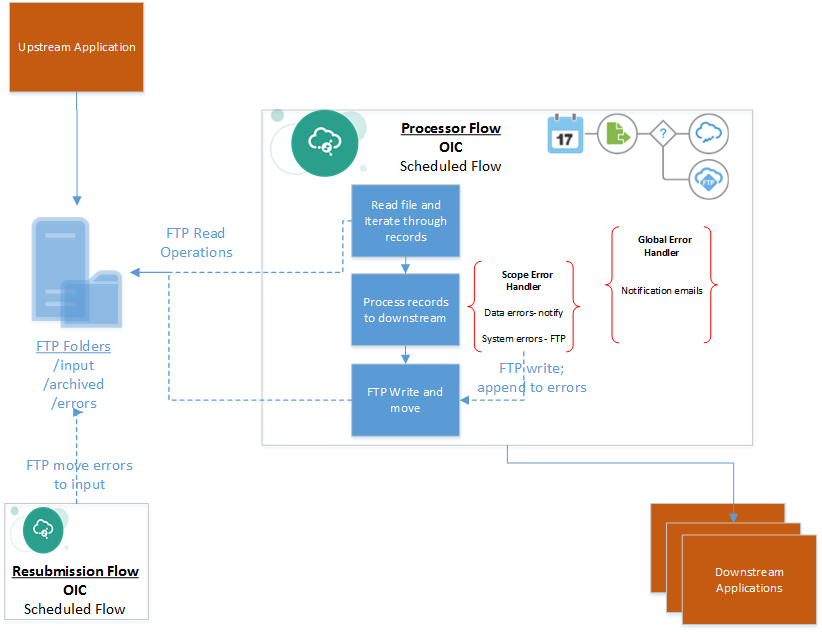
A scheduled integration retrieves the files and processes the records iterating through them. Any failed records are appended to an errors file in a separate location on FTP server. After reading all records from the input file, it is moved to archive on the FTP server.
A second re-submission scheduled OIC orchestration flow can simply move the files from error folder into input location to be reprocessed by the main orchestration flow.
These are simple examples intended to give a broad idea on how to design extended Error handling for OIC flows.
Overall, we have seen how OIC features can help design and develop integration flows that provide robust error handling capabilities.
Check out my new blog which builds on some of the concepts discussed here
Advanced Error handling and Scheduling Best Practices – Oracle Integration Cloud
References
- OIC Documentation – https://docs.oracle.com/en/cloud/paas/integration-cloud/index.html
- Scope handlers, Global fault handlers and Resubmission
- Feature Flags – Enabling the future today.. by Antony Reynolds
- Parking lot pattern – http://www.ateam-oracle.com/the-parking-lot-pattern
- Create Error feature – https://blogs.oracle.com/integration/working-with-create-error-activity-v2
