Data is fundamentally changing the way that organisations think and act. Business models and processes are being adjusted to monitorisation of information; the data driven economy is growing, and the acceleration of ‘leading with data’ is compounded by the emergence of Machine Learning algorithms to identify trends and perspectives across all data classes.
There is a real opportunity for organisations to capture the copious amount data being created from their applications, IOT devices and web traffic and to make sense of it.
Moving data is only one part of the opportunity; organising and structuring your information is a pre-requisite to mine the context found within it. So, when it comes to moving data at speed, extracting from the multiple data sources available and ingesting it to the designated target, you need the right tool.
In this blog I’ll discuss the two main processes used for batch data integration and provide an opinion on where best to use them. They are ETL: Extract, Transform & Load and ELT: Extract, Load & Transform.
At Oracle, our data integration products are Oracle Cloud Infrastructure Data Integration (OCI DI), Oracle Data Integrator (ODI) and Oracle Data Transforms (ODT); the latter being powered by ODI. Historically, the standard approach leveraged the ETL process, but as different type of data types emerged, there needed to be an alternative approach to cater for multiple use cases. However, the optimum process ultimately will be determined by the data and the SLAs that you have to work with.
So why is this important? Surely loading data to be accessed and analysed is straightforward, right? Well back in the day where we had on-premise backend infrastructure maybe, but what we’re seeing now is a proliferation of data being created at speed and mass from a multitude of sources. Knowing how to harness all this data is critical, so having a robust data management strategy is key to get the right information at the right time.
As the Technology industry has evolved, multiple tools appeared on the market to help with data growth, and with that came a multitude of workflows to try and manage and leverage the data. As more data is created, more silos appeared and what we saw is inconsistency of data management practices.
The tools I will reference in this blog are Oracle Cloud Infrastructure Data Integration (OCI DI) and Oracle Data Transforms (ODT).
OCI Data Integration is a cloud native managed cloud data integration service, that can extract, move, transform, and ingest data across the OCI ecosystem. The tool has been completely re-designed to cater for modern, as well as legacy workloads.
OCI Data Integration has an intuitive graphical codeless interface for designing your data flows. With the UI you can explore and prepare data before operationalising transformations and deploying them as tasks within applications. OCI Data Integration will also be able to schedule and orchestrate data tasks while defining dependencies between them, defining control flows, sequencing, and/or running tasks in parallel. OCI Data Integration optimises data tasks to be executed in the most optimal engine, whether it is pushed down to the database or executed on Spark via in memory processing to reduce the amount of data that is moved. It also provides enterprise capabilities, such as handling schema evolution through rules and patterns in your design to reduce the cost of maintaining your development and protecting your investment.
Oracle Data Transforms, which is part of Oracle Data Integrator provides a combined solution for building, deploying, and managing complex data sets or as part of data-centric architectures in a SOA, or business intelligence environment. However, as an enterprise solution it is not as mature as OCI Data Integration is. Therefore, it is not recommended for large-scale enterprise data sets.
Let’s now look at the two extract transform and load processes available.
Extract, Transform and Load (ETL)
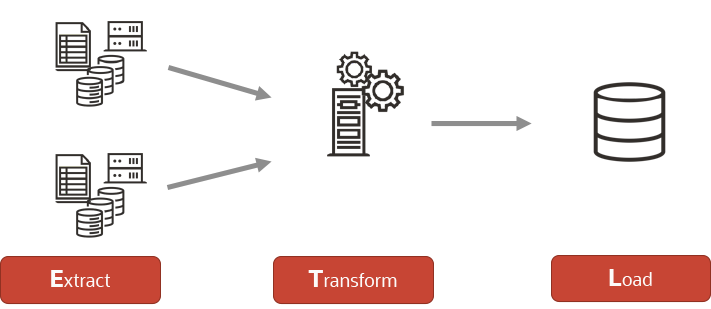
ETL essentially extracts the data from the source repository, transforms the dataset to conform to the warehouse schema, then loads it into the database tables. Once the data is loaded, it can then be accessed for whatever purpose is required. It is a standard and commonplace workflow process for optimising, enriching, and transforming data. This approach is often used in warehouse loading as it cleans out non-relevant information before loading it into tables. ETL is best suited for when compliance and data protection legislation is in force, as it allows the omission of sensitive/non-relevant information before it is loaded to the target system. This provides an element of protection when personal identifiable information (PII) is located with non-PII, which you need to analyse.
Once the data is loaded, it can then be used for business intelligence purposes, leveraging analytical platforms such as Fusion Analytics Warehouse (FAW) and Oracle Analytics Cloud (OAC) amongst others. Another valid and useful use case is with data science platforms for predictive analytics, which will be covered in a future blog. ETL is mature and well understood process; there are some overheads in terms of a required staging area for transformation, but once this has been completed it provides a fast load for near instant analysis as the dataset has already been structured in line with the database schema.
With regards to my previous comment on the need for fast loading of data, this is normally due to the vast amount of data being created in a small amount of time. Although ETL is a very good integration process, there are some challenges where speed is of the essence. ETL can be quite time-consuming, especially when developers are needed to write the code. OCI Data Integration tries to circumvent this through the intuitive and dynamic UI, providing a simplified drag-and-drop experience. Even so, planning is required to map out the transformation process stipulated by a potential diverse group of stakeholders; such as compliance/governance, the Line of Business and IT. Also, when designing an ETL process, one would need to understand the dependency and interdependency on other workflows and in most cases an ETL process would happen sequentially. Another dependency will be the operation and maintenance of ETL processes. As the number of dispersed data sources grows within an enterprise, so too will be the potential data pipelines required to centralise information to perform warehouse reporting needs. With this there will be a need for increased compute services to support the myriad of data pipelines. The data transformation step is the most compute intensive and is performed by the ETL engine, inclusive of data quality checks. With this, time lags can occur due to the bottleneck of processing. As the transformation is performed before it is loaded into the target system, the data needs to move across the network at least twice, once from the source system to the staging area for transformation, then once the data is transformed loading into the database. These are not showstoppers, but more align to dependencies when designing the optimum workflow for your extraction and load needs.
Extract, Load and Transform (ELT)
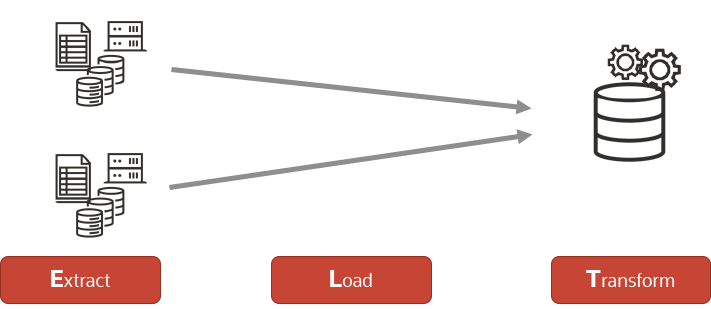
ELT is an alternative approach to data movement/processing to the standard ETL approach. We have started to see the Lakehouse architectures emerging that combine traditional Data Warehousing and Data Lakes; an ELT process can provide the ability to move the data, preserving the original format and loading it raw into the target system for use by business intelligence and big data analytics platforms. Whereas OCI Data Integration is an ETL tool, to achieve ELT, one must use either Oracle Data Transforms (ODT), which is an Oracle Data Integrator based integration tool that can be deployed from the Oracle Cloud Marketplace or OCI Data Integration.
For ODT, a data extraction can be done from a number of data sources and have it loaded directly into the Data Warehouse using native SQL operators where it can be analysed. With ELT, there is no need for a staging area, so the data is only transmitted across the network only once. If the transformation process is required, it can be preloaded in a staging area within the database where the transformation can happen before loading into the target database tables. This approach satisfies the need for speed and where the complete dataset needs to be analysed. Customers also enjoy the flexibility of this approach as it does allow for extraction and loading of all raw as and when it is required. As Lakehouse architectures emerge, a traditional ETL approach may not deliver the responses required to meet ever demanding SLAs, and the ELT process is an alternative way to meet these stringent needs.
However, there are a few constraints when dealing with ELT. (1) When there is a need to manage personal identifiable information. If the data sources contain sensitive information, then an ELT may not be satisfactory to meet the stringent global compliance and governance regulations that are in place across countries. (2) If you are dealing with large data sets, ELT will require further thought on securing the datasets as all raw data is loaded. This can be overcome by managing specific user and application access.
Distributed ETL (BIG DATA)
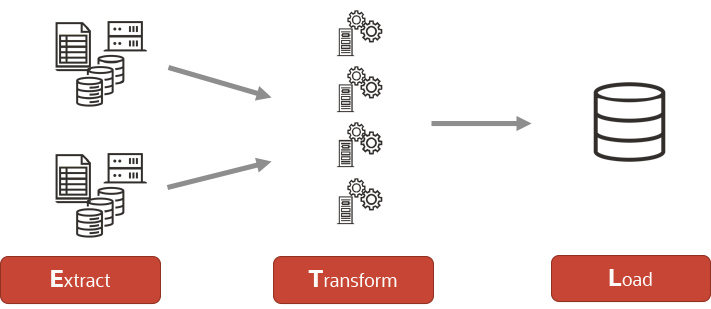
Distributed ETL
OCI Data Integration has the ability to operate as a distributed ETL. When it comes to very large datasets, using the right tool to load and transform is critical in delivering outcomes you need. For example, a widely accepted distributed data processing framework is Apache Spark. Apache Spark is a multi-language engine for executing data engineering, data science, and machine learning on single-node machines or clusters.
At Oracle we have OCI Data Flow which is a fully managed Apache Spark service that delivers distributed data processing on very large datasets, without the need to deploy or manage infrastructure. OCI Data Flow manages Spark job processes end to end; provisioning, network set-ups and ‘teardowns’ when the jobs are complete. It will also manage the storage and security for you, so there is more time to focus on analysing your information.
Spark has become the leading framework for Big Data processing and OCI Data Flow is the simplest way to run Spark in the Cloud.
OCI Data Integration enables you to create and orchestrate Spark jobs in a code-free graphical user interface. These tasks can be pushed and executed in a distributed OCI Data Flow architecture. By using OCI Data Integration to manage the Spark jobs via OCI Data Flow enables and delivers a Distributed computing ETL process.
Conclusion
When managing your data integration needs, there are different approaches that you could leverage. You need to pick a tool that allows you to extract and load your data sets based on the needs/outcomes, as well as the constraints you will deal with, such as data privacy, etc.
Oracle Cloud Infrastructure (OCI) Data Integration can deliver both ETL, ELT and Distributed ETL, being a one-stop tool for many data integration requirements.
First published on 2022-09-30

