Validation
-
ODI Version 12.2.1.4.200721.1540
-
Oracle GoldenGate 12c (12.3.0.1)
Introduction
The best option for ODI Changed Data Capture is to leverage Oracle GoldenGate. To understand how to best leverage the out-of-the-box integration between ODI and GoldenGate, we will review how ODI handles CDC with an in depth explanation of the JKMs principles, then expand this explanation to the specifics of the ODI-GoldenGate integration.
Understanding the ODI JKMs and how they work with Oracle GoldenGate
ODI is an ELT product. As such, it does not have its own transformation engine: data processing is done by leveraging the environment where the data is extracted from or loaded to (whether that environment is a database, an XML file, a JMS message or a Hadoop cluster). When it comes to the detection of changes in a source system, it is only natural that ODI on its own would not have proprietary mechanisms for that detection. ODI once again leverages other existing components, and creates an infrastructure to identify and process the changes that these components are detecting. We are reviewing here the details of this infrastructure, with an emphasis on how this infrastructure is leveraged when combining ODI with GoldenGate for the detection and delivery of the changes.
1. Understanding ODI JKMs
All the code generated by ODI is defined by a family of templates called Knowledge Modules. The Journalizing Knowledge Modules (JKM) are the KMs used when Changed Data Capture (CDC) is required for the data integration projects.
There are two journalizing modes for the JKMs: simple mode, and consistent set mode. Before going into the specifics for each mode, let’s review the common ground.
1.1 Infrastructure and key concepts
Rather than storing a copy of the entirety of the records that are changed, ODI will only require that the Primary Key of the changed records be stored in its infrastructure. If no primary key is available in the source system, any combination of columns that uniquely identifies the records can be used (in that case a primary key is defined in ODI, without any need to create a matching key in the database).
To store these Primary Keys the JKM will create a table named after the source table with a J$ prefix. ODI also creates views that join this J$ table with the original table so that one simple select statement can extract all the columns of the changed records. ODI automatically purges the content of the J$ table when the records have been processed.
ODI also maintains a list of subscribers to the changes the same way messaging systems work: each target application that requires a copy of the changes can be assigned a subscriber name. When consuming the changes, applications filter the changes by each providing their own subscriber name. In that case, when performing a purge, only the changes processed by all subscribers are removed from the J$ table (in other words, as long as at least one subscriber has not consumed a changed record, that record remains in the J$ table). Different subscribers can safely consume changes at their own pace with no risk of missing changes when they are ready for their own integration cycle. Figures 1 to 3 illustrate the consumption by 2 subscribers with different integration cycles and shows how purges are handled.
For the purpose of our illustration we assume that we have two subscribers: GL_INTEGRATION and DWH_INTEGRATION. GL_INTEGRATION consumes the changes every hour, 15 minutes past the hour. DWH_INTEGRATION consumes the changes once a day at 8:00pm. First, the GL_INTEGRATION processes all available changes at 12:15 PM:

Figure 1: Changes processed by the first subscriber.
As more changes appear in the J$ table, GL_INTEGRATION continues to process the new changes at 1:15 PM.

Figure 2: More changes processed by the first subscriber.
At the end of the day, the subscriber DWH_INTEGRATION consumes all the changes that have occurred during the day.

Figure 3: Changes processed by the second subscriber followed by a purge of the consumed records.
In the above example, if changes had occurred before 8:00pm, but after GL_INTEGRATION last processed the changes (i.e. 7:15pm) then these changes would not be purged until GL_INTEGRATION has processed them all (i.e. 8:15pm)
To process the changes, ODI applies a logical lock on the records that it is about to process. Then the records are processed and the unlock step defines if the records have to be purged or not, based on other subscribers consumption of the changes.
Two views are created: the JV$ view and the JV$D view.
The JV$ view is used in the mappings where you select the option Journalized data only. Figure 4 shows where to find this option in the Physical tab of the mappings:

Figure 4: Extracting only the changes from the source table.
The code generated by ODI uses this view instead of the original source table when this option is selected. The JV$ view joins the J$ table with the source table on the primary key. A filter in Logical tab of the mappings allows the developers to select the subscriber for which the changes are consumed, as illustrated in figure 5 below:
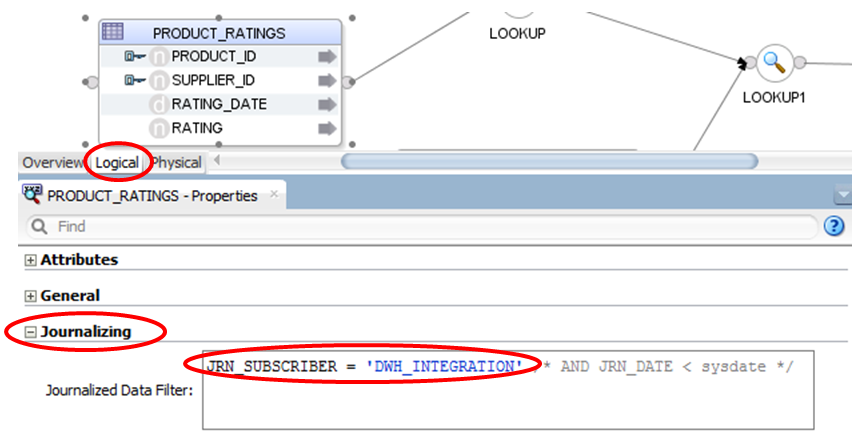
Figure 5: Selecting the subscriber name in the mapping options to consume changes.
The subscriber name does not have to be hard-coded: you can use an ODI variable to store this name and use the variable in the filter.
The JV$D view is used to show the list of changes available in the J$ table when you select the menu Journal Data from the CDC menu under the models and datastores. Figure 6 shows how to access this menu:

Figure 6: viewing the changes from the graphical interface.
1.2 Simple CDC
Simple CDC, as the name indicates, is a simple implementation of the infrastructure described above. This infrastructure works fine if you have:
-
One single subscriber
-
No dependencies between records (Parent-child).
Because of these limitations though, the most recent and most efficient JKMs provided out of the box with ODI are all Consistent set JKMs. One important caveat with simple CDC JKMs is that they create one entry per subscriber in the J$ table for every single changed row. If you have two subscribers, each change generates two records in the J$ table. Having three subscribers means three entries in the J$ table for each change. You can immediately see that this implementation works for basic cases, but it is very limited when you want to expand your infrastructure.
When using Simple CDC JKMs, the lock, unlock and purge operations are performed in the IKM: each IKM has the necessary steps for these operations, and these steps are only executed if:
-
Journalizing is selected in the interface, as described above in figure 4;
-
The JKM used for journalizing in the model that contains the source table is a Simple CDC JKM
1.3 Consistent set CDC
Consistent Set CDC addresses the two limitations of simple CDC:
-
Dependencies between parent and child records
-
Handling of more than one subscriber.
1.3.1 Parent-Child relationship
There are two conflicting requirements when processing parent and child records:
-
Parent records must be processed first, or child records cannot be inserted (they would be referencing invalid foreign keys).
-
ODI needs to mark the records that are about to be processed (This is the logical lock mentioned earlier), and then process them. But as we are processing the parent records, changes to additional parent and children can be written to the CDC tables. The challenge is that by the time we lock the children records in order to process them, the parent records for the last arrived changes have not been processed yet. Figure 7 below illustrates this: if ODI starts processing the changes in the Orders table at 12:00:00, and then starts processing the changes in the Order Lines table at 12:00:02, the parent record for order lines 4 and 5 is missing in the target environment: order # 3 had not arrived yet when the Orders changes were processed.

Figure 7: Parent and children records arriving during the processing of changes
When you define the parameters for consistent set CDC, you have to define the parent-child relationship between the tables. To do so, you have to edit the Model that contains these tables and select the Journalized Tables tab. You can either use the Reorganize button to have ODI compute the dependencies for you based on the foreign keys available in the model, or you can manually set the order. Parent tables should be at the top, children tables (the ones referencing the parents) should be at the bottom.
In Figure 8 we see a Diagram that was created under the model that hosts the journalized tables to represent the relationships between the tables. To reproduce this, create a Diagram under your Model, then drag and drop the selected tables in that diagram: the foreign keys will automatically be represented as arrows by the ODI Studio.
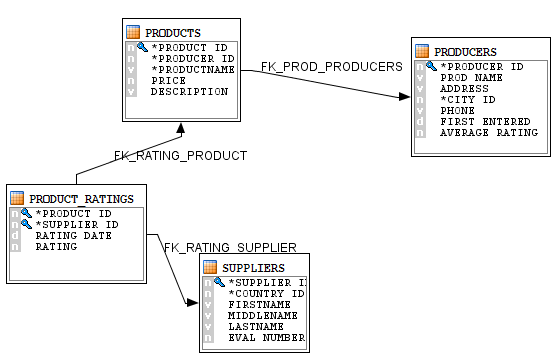
Figure 8: ODI Diagram that represents the parent-child relationship in a set of tables.
In the illustration shown in figure 9 we would have to move PRODUCT_RATINGS down the list because of its reference to the SUPPLIERS table.
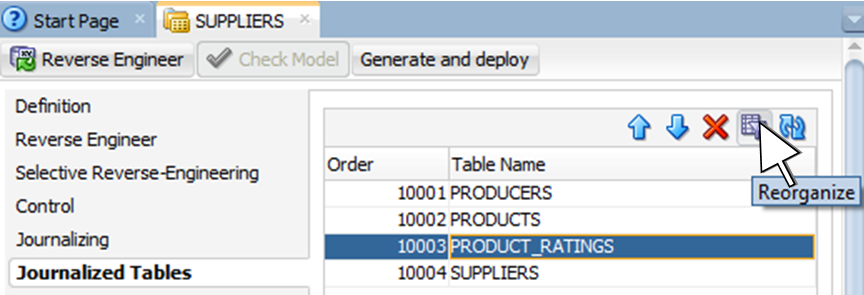
Figure 9: Ordering CDC tables from parent to child
Once the tables are ordered, the Consistent Set JKMs can “lock” the records based on this order: children records first, then the parent records. From then on it is safe to process the parent records, followed by the children records knowing that none of these children are missing their references. If more parent and children records are delivered to the J$ tables while the data is being processed (as was the case in Figure 7 with order #3 and the matching order lines), the new records are not locked and are ignored until the next iteration of the integration process. This next iteration can be anywhere from a few seconds later to hours later, depending on latency requirements.
Another improvement over simple CDC is that consistent set CDC does not duplicate the records in the J$ table when multiple subscribers are registered. Instead, ODI maintains window_ids that are used to identify when the records have been inserted in the infrastructure. Then it is only a matter of knowing which window_ids have been processed by which subscriber.
When the records of a set (parents and children records) are about to be processed, children records and parent records are logically locked. The KMs do the following operations:
-
Make sure that all records have a window_id, then identify the highest available window_ids (this is the Extend Window operation)
-
Define the array of window_ids to be processed by the subscribers (this is the Lock Subscriber operation).
These operations are performed in the packages before processing the interfaces where CDC data is processed as shown in Figure 10. After the data has been processed, the subscribers must be unlocked and the J$ table can be purged of the consumed records.
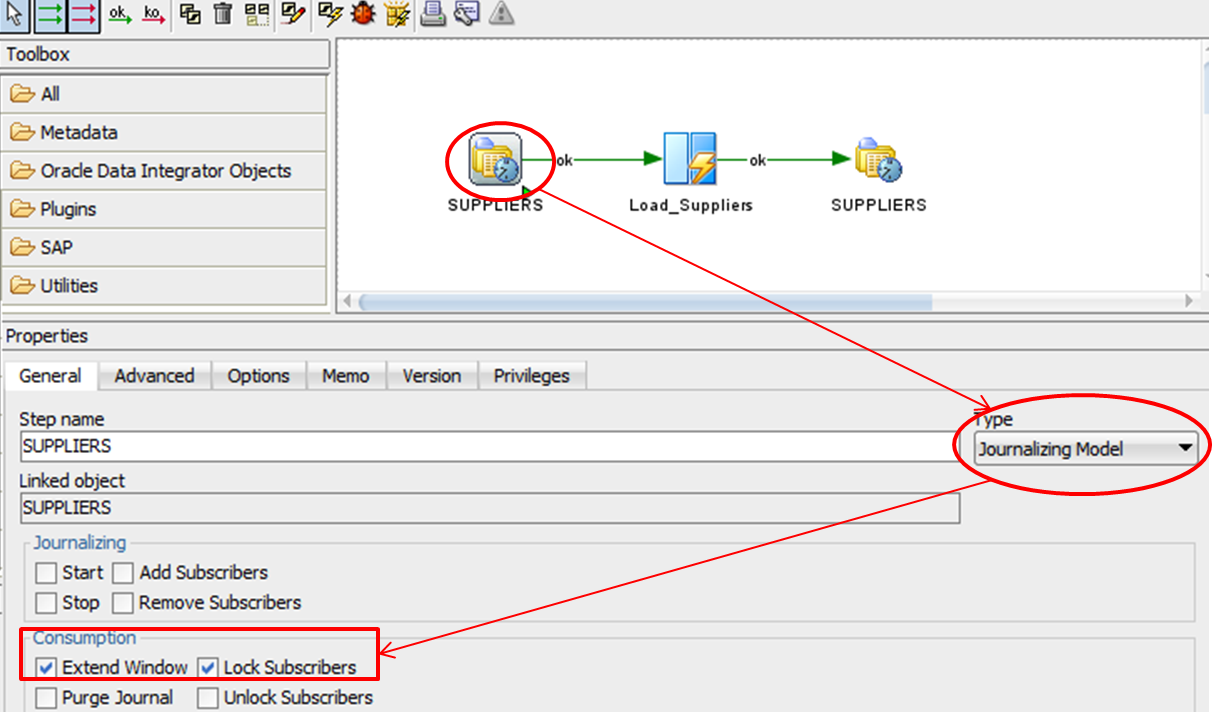
Figure 10: Example of a package for consistent set CDC.
To add these operations to a package, drag and drop the Model that contains the CDC set, then set the Type to Journalizing Model and select the appropriate options in the consumption section, as shown in Figure 10. You can drag and drop the model twice to separate the two operations. Note that in this case, the Extend Window operation must be done before the Lock Subscriber operation.
We will now look at how the Extend Window and Lock Subscriber package steps work:
Extend window
Either the window_id column of the J$ table is updated by the detection mechanism (as is the case with GoldenGate JKMs) or it is not (as is the case with trigger based JKMs). In all cases, the SNP_CDC_SET table is first updated with the new computed window_id for the CDC Set that is being processed. The window_id is computed from the checkpoint table for GoldenGate JKMs or is based on an increment of the last used value (found in the SNP_CDC_SET table) for other JKMs.
For non GoldenGate JKMs, all records of the J$ table that do not have a window_id yet (the value would be null) are updated with this new window_id value so that the records can be processed: these are records that were written to the J$ table after the last processing of changes and were never assigned a window_id.
Again, GoldenGate writes this window_id as it inserts records into the J$ table.
Lock subscriber
For all JKMs, the subscribers have to be locked: their processing window are set to range between the last processed window_id (which is the “minimum” window_id) and the newly computed window_id (which is the “maximum” window_id).
Unlock and purge
After processing, Unlocking the subscribers only amounts to overwriting the last processed window_id with the newly computed window_id (this way the next time we want to process changes, the “minimum window_id” is the one we had computed as the maximum window_id for the completed run). The “purge” step makes sure that the records that have been processed by all subscribers are removed from the J$ tables (all records with a window_id less than or equal to the lowest processed window_id across all subscribers)
Now that we understand the mechanics of ODI CDC, we can look into the details of the infrastructure.
2. Details of the Infrastructure
2.1 Simple CDC
Simple CDC requires only 2 tables and 2 views. The first table is for the list of subscribers and the tables they each monitor, the second table (J$) lists the changes for each source table that is monitored (there is one such table for each monitored source table). The views are used to either see the changes from the ODI Studio, or to consume the changes in the mappings.
The subscribers table is created in the Work Schema of the Default Schema for the data server. To identify the Default Schema, look under the data server definition in the physical architecture of the Topology Navigator: the Default Schema is marked with a checkmark. If you edit the schema, the Default checkbox is selected. As such, there will be a single, shared subscribers table for all the schemas on that server.
The J$ table and the two views are created for each table that is journalized. These are created in the Work Schema associated to the Physical Schema where the source table is located.
2.1.1 The Subscribers Table
When you register a subscriber to consume changes for a give table, the subscriber name and the name of the table are added to the SNP_CDC_SUBS table.
| SNP_CDC_SUBS |
|
| JRN_TNAME (PK) | Name of the table monitored for changes |
| JRN_SUBSCRIBER (PK) | Name of the subscriber |
| JRN_REFDATE | Last update of the record |
| JRN_ROW_COUNT | Number of rows in the journalizing tables for this subscription |
| JRN_DATA_CMD | Placeholder for the SQL query to retrieve the changed data |
| JRN_COUNT_CMD | SQL query to update the JRN_ROW_COUNT column |
2.1.2 The J$ tables
For simple CDC, the J$ tables contains the PK of the changed records in the table that is monitored for changes, along with the name of the subscriber for whom that change is recorded.
The JRN_CONSUMED is used to logically lock the records: when the records are inserted in the J$ table, the value is set to 0. Remember, for Simple CDC the lock/unlock operations are performed by the IKMs. When the IKMs lock the records, the value is changed to 1. The “unlock” process only purges records with a value equal to 1.
The JRN_FLAG column indicates the type of change detected in the source system. Deleted records are marked with a ‘D’. Inserts and updates are marked with an ‘I’: the IKM differentiates between inserts and updates based on the content of the target table: there could have been more than one change in the source system between two ODI integration cycles, for instance a new record can be inserted and then updated before the new cycle gets started. In that case, even though the last event in the source system is an update, the operation that is needed on the target side is an insert with the latest values found in the source system.
| J$<SOURCE_TABLE_NAME> |
|
| JRN_SUBSCRIBER | Name of the subscriber who subscribed to the table changes |
| JRN_CONSUMED | Boolean flag. Set to 0 when the records are inserted, incremented to 1 when the records are marked for consumption (or “locked”) |
| JRN_FLAG | Type of operation in the source table (D=deleted, I= inserted or updated) |
| JRN_DATE | Date and time of the change |
| PK_x | Column x of the primary key (each column of the primary key of the source table is represented as a separate column in the J$ table) |
This shows that ODI does not replicate the transactions; it does an integration of the data as they are at the time the integration process runs. Oracle GoldenGate replicates the transactions as they occur on the source system.
2.1.3 The JV$ View
The JV$ view is the view that is used in the mappings where you select the option Journalized data only. Records from the J$ table are filtered so that only the following records are returned:
-
Only Locked records : JRN_CONSUMED=’1’
-
If the same PK appears multiple times, only the last entry for that PK (based on the JRN_DATE) is taken into account. Again the logic here is that we want to replicate values as they are currently in the source database. We are not interested in the history of intermediate values that could have existed.
An additional filter is added in the mappings at design time so that only the records for the selected subscriber are consumed from the J$ table, as we saw in figure 5.
2.1.4 The JV$D view
Similarly to the JV$ view, the JV$D view joins the J$ table with the source table on the primary key. This view shows all changed records, locked or not, but applies the same filter on the JRN_DATE column so that only the last entry is taken into account when the same record has been modified multiple times since the last consumption cycle. It lists the changes for all subscribers.
2.2 Consistent Set CDC
The infrastructure for consistent set CDC is richer to accommodate more complex situations.
Once again, all infrastructure table (SNP_xxx) are created in the Work Schema of the Default Schema for the data server. As such they are shared resources for all schemas defined under the data server. The J$ table and the associated views are created in the Work Schema associated to the Physical Schema where the source table is located.
Now let’s look at the different components of this infrastructure.
2.2.1 The CDC set table
This table keeps track of the latest (and highest by the same token) window_ids used for a given CDC set. It is updated during the Extend Window step of the packages.
| SNP_CDC_SET |
|
| CDC_SET_NAME (PK) | Name of the CDC Set |
| CUR_WINDOW_ID | Last window_id that has been used for this CDC set |
| CUR_WINDOW_ID_DEL | Last Window_id used to compute delete consistency |
| CUR_WINDOW_ID_INS | Last Window_id used to compute insert/update consistency |
| RETRIEVE_DATA | Command to execute in order to retrieve the journal data (used by the SnpsRetrieveJournalData API |
| REFRESH_ROW_COUNT | Command to execute in order to refresh the row count(used by the SnpsRefreshJournalData API |
2.2.2 The subscribers table
This table lists the subscribers, and for each subscriber it references the data set to which the subscriber subscribed, along with the minimum and maximum window_id for this combination of subscriber and CDC set.
| SNP_CDC_SUBS |
|
| CDC_SET_NAME (PK) | Name of the CDC Set |
| CDC_SUBSCRIBER (PK) | Name of the subscriber who subscribed to the CDC Set |
| CDC_REFDATE | Last update of the record |
| MIN_WINDOW_ID | Window_ids under this one should be ignored |
| MAX_WINDOW_ID | Maximum Window_id used by this subscription |
| MAX_WINDOW_ID_DEL | Maximum Window_id to take into consideration when looking at consistency for deletes |
| MAX_WINDOW_ID_INS | Maximum Window_id to take into consideration when looking at consistency for inserts / updates |
| CDC_ROW_COUNT | Number of rows in the journalizing tables for this subscription |
After the Extend Window step updated in the SNP_CDC_SET table for the current CDC set, the Lock Subscriber step in the packages updates the maximum window_ids of the SNP_CDC_SUBS table with the same values for the current subscriber.
Only the changes from the J$ table that have a window_id between the minimum and maximum window_id recorded in the SNP_CDC_SUBS table are processed. Once these changes have been processed and committed, the maximum window_id is used to overwrite the minimum window_id (this is done in the Unlock Subscriber step of the package). This guarantees that the infrastructure is ready for the next integration cycle, starting where we left off.
2.2.3 The table listing the content of a CDC set
This table lists the tables that are journalized in a given data set.
| SNP_CDC_SET_TABLE |
|
| CDC_SET_NAME | Name of the CDC Set |
| FULL_TABLE_NAME (PK) | Full name of the journalized table. For instance SUPPLIERS.PRODUCT_RATINGS |
| FULL_DATA_VIEW | Name of the data view. For instance ODI_TMP.JV$DPRODUCT_RATINGS |
| RETRIEVE_DATA | Command to execute in order to retrieve the journal data (used by the SnpsRetrieveJournalData API |
| REFRESH_ROW_COUNT | Command to execute in order to refresh the row count(used by the SnpsRefreshJournalData API |
2.2.4 The table listing the infrastructure objects
This table lists all the CDC infrastructure components associated to a journalized table.
| SNP_CDC_OBJECTS |
|
| FULL_TABLE_NAME (PK) | Name of the Journalized table |
| CDC_OBJECT_TYPE (PK) | Source table, view or data view, OGG component |
| FULL_OBJECT_NAME | Name of the object whose type is CDC_OBJECT_TYPE |
| DB_OBJECT_TYPE | TABLE/VIEW/TRIGGER/OGG EXTRACT/OGG REPLICAT/OGG INIT EXTRACT |
This table is leveraged to make sure that ODI does not attempt to recreate an object that has already been created (see section 4.1 Only creating the J$ tables and views if they do not exist).
2.2.5 The J$ tables
For consistent CDC, the J$ tables contain the PK of the changed records along with a window_id that is updated to make sure that this records is processed in the appropriate order. Depending on the JKMs, the window_id can be updated by the mechanism used to detect the changes (as is the case for the GoldenGate JKMs) or during the Extend Window step of the package (in which case it is an increment of the last used value).
| J$<SOURCE_TABLE_NAME> |
|
| WINDOW_ID | Batch order defining when to process the data |
| PK_x | Column x of the primary key (each column of the primary key of the source table is represented as a separate column in the J$ table) |
2.2.6 The Views
The JV$ view is the view that is used in the mappings where you select the option Journalized data only. Records are filtered so that only the following records are returned:
-
Records where the window_id is between the minimum and maximum window_id for the subscribers;
-
If the same PK appears multiple times, only the last entry for that PK is taken into account. The logic here is that we want to replicate values as they currently are in the source database: we are not interested in the history of intermediate values that could have existed.
A filter created in the mappings allows the developers to select the subscriber for which the changes are consumed, as we saw in figure 5.
The JV$D view uses the same approach to remove duplicate entries, but it shows all entries available to all subscribers, including the ones that have not been assigned a window_id yet.
3. Focus on ODI JKMs for GoldenGate
The main benefit for ODI to leverage Oracle GoldenGate is that GoldenGate is the least intrusive product on the market to continuously extract data from a source system and replicate the transactions with the best possible performance.
3.1 Why GoldenGate?
We would not be doing justice to GoldenGate by trying to explain its many benefits in just a few lines. The GoldenGate documentation contains a very good introduction to the technology available here: http://docs.oracle.com/goldengate/1212/gg-winux/GWUAD/wu_about_gg.htm . If you are interested in best practices, real life recommendations and in depth understanding of GoldenGate, our experts concentrate their work here: http://www.ateam-oracle.com/di-ogg/.
The important elements of integrating with GoldenGate from an ODI perspective are the following:
-
Low impact on the source system: GoldenGate reads the changes directly from the database logs, and as such does not require any additional database activity.
-
Decoupled architecture: GoldenGate continuously replicates the transactions occurring on the source system, making these changes available to ODI as needed without the need for ODI to run a (potentially costly) SQL query against the source system when the ODI integration cycle starts. If part of the infrastructure is down, the impact on the other elements is minimal: the GoldenGate Capture process is independent from its delivery process, and the ODI processes are independent from the GoldenGate processes. This also allows for real time capture on the source system and scheduled delivery in the target system.
-
Performance of the end-to-end solution: even though the large majority of ODI customers run their ODI processes as batch jobs, some customers are reducing the processing windows continuously. Using GoldenGate for CDC allows for unique end-to-end performance, with customers achieving under-10 seconds end-to-end latency across heterogeneous systems: this includes GoldenGate detection of the changes, replication of the changes, transformations by ODI and commit in the target system.
-
Heterogeneous capabilities: both ODI and GoldenGate can operate on many databases available on the market, allowing for more flexibility in the data integration infrastructure.
3.2 Integration between ODI and OGG
The main components of the integration between ODI and GoldenGate are the following:
-
The ODI JKMs generates the necessary files for GoldenGate to replicate the data and update the ODI J$ tables (oby and prm files for the capture, pump and apply processes), including the window_id
-
These files instruct GoldenGate to write the PK of the changed records and to update the window_id for that change. The window_id is computed by concatenating the sequence number and the RBA from the GoldenGate checkpoint file with this expression:
WINDOW_ID = @STRCAT(@GETENV(“RECORD”, “FILESEQNO”), @STRNUM(@GETENV(“RECORD”, “FILERBA”), RIGHTZERO, 10))
-
If you are using OGG Online JKMs, ODI can issue the commands using the GoldenGate JAgent and execute these commands directly. If not, ODI generates a readme file along with the oby and prm file. This file provides all the necessary instructions to configure and start the GoldenGate replication using the generated files.
-
If you already have a GoldenGate replication in place, you can read the prm files generated by ODI to see what needs to be changed in your configuration so that you update the J$ tables (or read the next section for an explanation of how this works).
3.3 How does GoldenGate update the J$ tables
ODI creates a prm file for the apply process that contains basic replication instructions.
ODI writes two maps in that prm file. The first one instructs GoldenGate to copy the data from the source table into the staging tables.
map <Source_table_name>, TARGET <Target_table_name>, KEYCOLS (PK1, PK2, …, PKn);
The second one makes sure that the J$ table is updated at the same time as the staging table. GoldenGate in this case has two targets when it replicates the changes.
map <Source_table_name>, target <J$_Table_name>, KEYCOLS (PK1, PK2,…,PKn, WINDOW_ID), INSERTALLRECORDS, OVERRIDEDUPS, COLMAP ( PK1 = PK1, PK2 = PK2, ... PKn=PKn, WINDOW_ID = @STRCAT(@GETENV("RECORD", "FILESEQNO"), @STRNUM(@GETENV("RECORD", "FILERBA"), RIGHTZERO, 10)) );
If you already have GoldenGate in place to replicate data from the source tables into a staging area, you may not be interested in using the files generated by ODI. You have already configured and fine tuned your environment, you do not want to override your configuration. All you need to do in that case is to add the additional maps for GoldenGate to update the ODI J$ tables.
3.4 Evolution of the GoldenGate JKMs between ODI 11g and ODI 12c
There is a deeper integration between ODI and GoldenGate in the 12c release of ODI than what was available with the 11g release. One immediate consequence is that the JKMs for GoldenGate have evolved to take advantage of features that now become available:
-
In ODI 11g the source table for an initial load was different from the source table used with GoldenGate for CDC: the GoldenGate replicat table had to be used explicitly as a source table in CDC configurations. With the 12c implementation of the GoldenGate JKMs, the same original source table is used in the mappings for both initial loads and incremental loads using GoldenGate. For CDC, the GoldenGate source becomes the source table in the mappings for CDC. The GoldenGate replicat is considered as a staging table and as such is not represented in the ODI mappings anymore.
-
The new JKMs allow for online or offline use of GoldenGate: in online mode, ODI communicates directly with the GoldenGate JAgent to distribute the configuration parameters. The offline mode is similar to what was available in ODI 11g.
4. Elements to look for in the ODI JKM if you want to go further
To illustrate JKM internal workings, we are looking here at code of some of the Knowledge Modules delivered with ODI 12.1.2.0
4.1 Only creating the J$ tables and views if they do not exist
Traditionally in ODI KMs, tables and views can be created with the option to Ignore Errors so that the code does not fail if the infrastructure is already in place. This approach does not work well in the case of JKMs where we do want to know that the creation of a J$ table (or view) fails, but we will continuously add tables and views to the environment. What we want is to ignore the tables that have already been created, and only create the ones that are needed.
If you edit the JKM Oracle to Oracle Consistent (OGG) and look at the task Create J$ Table you can see that there is code in the Source command section as well as for the Target command section. The target command creates the table, as you would expect. The source command only returns a result set if the J$ table we are about to create in not referenced in the SNP_CDC_OBJECTS table. If there is no result set from the source command, the target command is not executed by ODI: the standard behavior in KM and procedures tasks is that the target command is executed once for each element of the result set returned from the source command (if there is a source command). Zero elements in the result set mean no execution.
4.2 Operating on Parents and Children tables in a CDC set
Some operations require that ODI processes the parent table first; others require that the child tables are processed first. If you edit the JKM Oracle Consistent and look at the task Extend Consistency Window (inserts), under the Consumption tab, you can see that that the window_ids are applied in Descending order, as shown in Figure 11. The reverse operation further down in the KM, Cleanup journalized tables, is done in Ascending order.
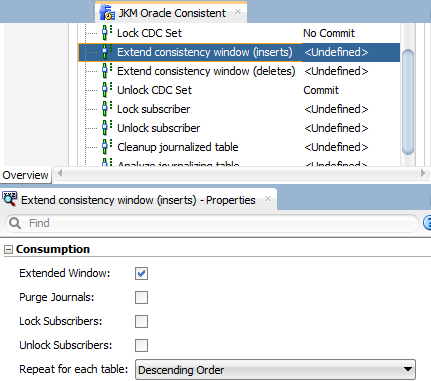
Figure 11: Repeating the code for all tables of the CDC set in the appropriate order
Note that since GoldenGate updates the window_ids directly for ODI, the matching step does not exist in the GoldeGate JKMs. But the same technique of processing tables of the set in the appropriate order is leveraged when creating or dropping the infrastructure (look at the Create J$ and Drop J$ tasks for instance in the GoldenGate JKMs).
Conclusion
As you can see the ODI CDC infrastructure provides a large amount of flexibility and covers the most complex integration requirements for CDC. The out-of-the-box integration with Oracle GoldenGate helps developers combine both products very quickly without the need for experts to intervene. But if you need to alter the way the two products interact with one another, JKMs are the key to the solution you are dreaming about.
For more ODI best practices, tips, tricks, and guidance that the A-Team members gain from real-world experiences working with customers and partners, visit “Oracle A-Team Chronicles for ODI”. For Oracle GoldenGate, visit “Oracle A-Team Chronicles for GoldenGate”
First published on 2014-01-21
