Validation
-
ODI Version 12.2.1.4.200721.1540
-
Oracle DB System 19.7.0.0
Introduction
With no middle tier required in the ODI architecture, the most common question from people who are new to ODI is where to install the standalone agent: source, target or middle tier systems? We look here at different possible architectures and provide the best choices accordingly.
Understanding Where to Install the ODI Standalone Agent
Source, Target or Middle tier?
Source systems be dispersed throughout the information system: connection from one source system to an other one is never guaranteed. This usually make source systems a less than ideal location for the ODI agent. Dedicated systems can work, but if they are independent of the database servers involved in the ETL processes, then the infrastructure is dependent on physical resources that are not tightly coupled with the ETL processes. This means that there are more components to provision, monitor and maintain over time. A simple answer then is that installing the agent on the target systems makes sense. In particular if we are talking of a data warehousing environment, where most of the staging of data will already occur on this target system.
But in the end, this simple answer is a convenience, not an all be all. So rather than accepting this as an absolute truth, we will look into how the agent works and from there provide a more nuanced answer to this question.
For the purpose of this discussion we are considering the Standalone version of the agent only – the JEE version of the agent runs on top of a Weblogic server, which pretty much defines where to install the agent… but keep in mind that in the same environment standalone and JEE agents can be combined. Also note that the JEE agent architecture addresses the limitation described above when the agent is installed neither on the source nor on the target systems. For one, Weblogic would not be dedicated solely to the ODI agent. In addition, the WebLogic cluster will provide the necessary High Availability infrastructure to guarantee that the agents and their schedules are always available.
In addition, ODI 12c introduces the notion of Collocated agents: these can be viewed as Standalone agents that can be managed and monitored from WebLogic Server and Enterprise Manager. Naturally the recommendations for the location of the Standalone agent will also apply to the Collocated agents. For more on the different types of ODI agents see ODI agents: Standalone, JEE and Colocated
First we will look into connectivity requirements. Then we will look into how the agent interacts with the environment: flat files, scripts, utilities, firewalls. And finally we will illustrate the different cases with real life examples.
Understanding Agent Connectivity Requirements
The agent has to perform up to a number of operations for a scenario to run:
-
Connect to the repository (always)
-
Connect to the source and target systems (always, the minimum requirement will be to connect to the databases to send DDL and DML for execution by the systems)
-
Access the data via JDBC (if needed – depends on the Knowledge Modules that are used in the mappings of the scenario).
Connection to the repository
The agent will connect to the repository to perform the following tasks:
-
Retrieve from the repository the code of the scenarios that are executed
-
Complete the code generation based on the context that was selected for execution
-
Write the generated code in the operator tables
-
After the code has been executed by the databases, update the operator tables with runtime statistics and, if necessary, error messages returned by the databases or operating system.
ODI 12c improves dramatically the communication between the agents and the repository with blueprint caching and optimized logs generations. Nonetheless the same connection requirements remain.
To perform all these operations, the agent will use JDBC to connect to the repository. The parameters for the agent to connect are defined when the agent is installed. For a 12c standalone agent, these parameters are managed with the config.sh script (or config.cmd on Windows) available in ORACLE_HOME/oracle_common/common/bin. For earlier releases of ODI these parameters are maintained manually by editing the file odiparams.sh (or odiparams.bat on Windows) found in the ORACLE_HOME/oracledi/agent/bin directory.
What does this mean for the location of the agent?
Since the agent uses JDBC to connect to the repository, the agent does not have to be on the same machine as the repository. The amount of data exchanged with the repository is limited to logs generation and updates. In general this amounts to relatively little traffic, except in the case of near real time environments where the agent can be communicating extensively with the repository. In all cases, it is highly recommended that the agent be on the same LAN as the repository. To limit latency between the agent and the repository, make sure that the agent is physically close to the repository (and not a few miles away). Beyond that, the agent can be installed on pretty much any system that can physically connect to the proper database ports to access the repository.
Connection to sources and targets
Before sending code to the source and target systems for execution, the agent must first establish a connection to these systems. The agent will use JDBC to connect to all source and target databases at the beginning of the execution of a session. These connections will be used by the agent to send the DDL (create table, drop table, create index, etc.) and DML (insert into… select…from… where…) that will be executed by the databases.
What does this mean for the location of the agent?
As long as the agent is sending DDLs and DMLs to the source and target systems, once again it does not have to be physically installed on any of these systems. However, the location of the agent must be strategically selected so that it can connect to all databases, sources and targets. From a network perspective, it is common for the target system to be able to view all sources, but it is not rare for sources to be segregated from one another: different sub-networks or firewalls getting in the way are quite common. If there is no guaranty that the agent can connect to all sources (and targets) if it is installed on a source system, then it makes more sense to install it on one of the target systems. The DDL and DML activity described above requires a limited amount of physical resources (CPU, memory), so the impact of the agent on the system on which it is installed is quite negligible.
Conclusion: from an orchestration perspective, the agent could be anywhere in the LAN, but it is usually more practical to install it on the target server.
Data transfer using JDBC
ODI processes can use multiple techniques to extract from source systems and load data into target systems: JDBC is one of these techniques. If the mappings executed by the agent use JDBC to move data from source to target, then the agent itself establishes this connection: as a result the data will physically flow through the agent.
JDBC is never the most efficient way to transfer large volumes of data. Database utilities will always provide better performance and require fewer resources. It is always recommended to review Knowldege Modules selections made in your mappings and interfaces to make sure that only the most efficient KMs are used when transferring large volumes of data .Defaulting every data transfer to JDBC is never a good practice. In addition to being inefficient in terms of performance, JDBC will use the memory space allocated to the agent. The more JDBC processes you have running in parallel, the more memory is used by the agent. Before increasing the memory allocation for the agent, always double check which Knowledge Modules are being used, and how much data is processed with these Knowledge Modules. Replacing JDBC KMs with native utilities KMs will both address memory requirement and improve performance.
What does this mean for the location of the agent?
This is a case where we have to be more careful with the agent location. In all previous cases, the agent could have been installed pretty much anywhere as the performance impact was negligible. Now if data physically moves through the agent, placing the agent on either the source server or the target server will in effect limit the number of network hops required for the data to move from source to target.
Let’s take the example where the agent runs on a windows server, with a source on a mainframe and a target on Linux. Data will have to go over the network from the mainframe to the windows server, and then from the windows server to the Linux box. In data integration architectures, the network is always a limiting factor for performance. Placing the agent on either the source or the target server will help limit the adverse impact of the network.
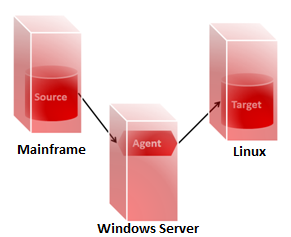
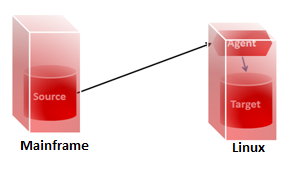
| Figure 1: JDBC access with remote ODI agent |
Figure 2: JDBC access with ODI agent on target |
Other considerations: accessing files, scripts, utilities
Part of the integration process often requires accessing resources that are local to a system: flat files that are not accessible remotely, local scripts and utilities. A very good example is the leverage of database bulk loading utilities for files located on a file server. Installing the agent on the file server along with the loading utilities allows ODI to bulk load the files directly from the server. An alternative is to share (or mount) the directories where the files and utilities are installed so that the agent can view them remotely. Keep in mind that mounted drives and shared network directories tend to degrade performance though.
What does this mean for the location of the agent?
It is actually quite common to have the ODI agent installed on a file server (along with the database loading utilities) so that it can have local access to the files. This is easier than trying to share directories across the network (and more efficient), in particular if when dealing with disparate operating systems.
Another consideration to keep in mind at this point is that there is no limit to the number of ODI agent any given environment: some jobs can be assigned to specific agents because they need access to resources that would not be visible to other agents. This is a very common infrastructure, where a central agent receives the job execution requests (maybe on the target server, or a JEE agent on WebLogic Server). Some of the scenarios can then leverage satellite agents in charge of very specific tasks.
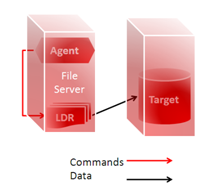
Figure 3: ODI agent loading flat files
Beyond databases: Big Data
In a Hadoop environment, execution requests are submitted to a NameNode. This Namenode is then in charge of distributing the execution across all DataNodes that are deployed and operational. It would be totally counter-productive for the ODI agent to try and bypass the NameNode. From that perspective, the best location for the ODI agent is to be installed on the NameNode.
The Oracle BigData appliance ships with the ODI agent pre-packaged so that the environment is immediately ready to use.
Firewall considerations
One element that seems pretty obvious is that no matter where the agents are located, it is important to make sure that the firewalls will let the agents access the necessary resources. More challenging can be the timeouts that some firewalls (or even servers in the case of iSeries) will have. For instance it is a common configuration for firewalls to drop connections that are inactive for more than 30 minutes. If a large batch operation is being executed by the database, the agent has no reason to overload the network or the repository with unnecessary activity while it’s waiting for the operation to be completed… but as a result the firewall could disconnect the agent from the repository or from the databases. The typical error in that case would appear as “connection reset by peer”. When experiencing such a behavior, think about reviewing firewall configurations with your security administrators.
Real life examples
We will now look into some real life examples, and define where the agent would best be located for each scenario.
Loading data into Exadata with external tables
We are looking here into the case where files have to be loaded into Exadata. An important point from an ODI perspective is that we first want to look into what makes the most sense for the database itself – then we will make sure that ODI can deliver.
The best option for Exadata in terms of performance will be to land the files on DBFS and take advantage of the performance of Infiniband for the data loads. From a database perspective, loading the files as external tables will give us by far the best possible performance.
Considerations for the agent
The key point here is that external tables can be created through DDL commands. As long as the files are on DBFS, they are visible to the database… (They would have to be for us to use External tables anyhow). Since the agent will connect to Exadata via JDBC, it can issue DDLs no matter where it is installed, on a remote server or on the Exadata appliance.
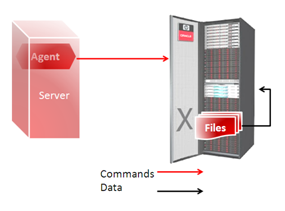
Figure 4: Remote ODI agent driving File Load
via external tables
Loading data with JDBC
There will be cases where volume mandates the use of bulk loads. Other cases will be fine using JDBC connectivity (in particular if volume is limited). Uli Bethke has a very good discussion on this subject here, even though his focus at the time was not to define whether to use JDBC or not.
One key benefit of JDBC is that it is the simplest possible setup: as long as the JDBC driver is in place and physical access to the resource is possible (file or database) data can be extracted and loaded. For a database, this means that no firewall prevents access to the database ports. For a file, this means that the agent has physical access to the files.
Considerations for the agent
The most common mistake for files access is to start the agent with a username that does not have the necessary privileges to see the files – whether the files are local to the agent or accessed through a shared directory on the network (mounted on Unix, shared on Windows).
Other than that, as we have already seen earlier, locate the agent so as to limit the number of network hops from source to target (and not from source to middle tier to target). So the preference for database-to-database integration is usually to install the agent on the target server. For file-to-database integration, have the agent and database loading utilities on the file server. If files and databases sources are combined, then it is possible to either have a single agent on the file server, or to have two separate agents, thus optimizing the data flows.
Revisiting external tables on Exadata with file detection.
Let’s revisit our initial case with flat files on Exadata. Let’s now assume that ODI must detect that the files have arrived, and that this detection triggers the load of the file.
Considerations for the agent
In that case, the agent itself will have to see the files. This means that either the agent will be on the same system as the files (we said earlier that the files would be on Exadata) or the files will have to be shared on the network so that they are visible on the machine on which the agent is installed. Installing the agent on Exadata is so simple that it is more often than not the preferred choice.

Figure 5: ODI agent on Exadata detecting new files
and driving loads via external tables
Conclusion
The optimal location for ODI standalone agents will greatly depend on the activities that the agent has to perform, but there are two locations that always work best:
- Target database
- File server
Keep in mind that an environment is not limited to a single agent – and more agents will enhance the flexibility of the infrastructure. A good starting point for the first agent will be to position it on the target system. Additional agents can be added as needed, based on the specifics of the integration requirements.
For more ODI best practices, tips, tricks, and guidance that the A-Team members gain from real-world experiences working with customers and partners, visit Oracle A-Team Chronicles for ODI.
First published on 2014-04-14
