The A-Team has received many requests for ‘guidance in providing secure and resilient failover for Cloud services’. This is the normal opening question when people ask for help in this area. Having spent a large part of my career in business continuity, many non-technical aspects need to be considered and addressed before one even starts to talk let alone deploy, an architecture to achieve failover.
In this blog, I will endeavour to cover several aspects when the business and compliance department asks for a resilient architecture. I start with the business and not the IT department, because, all technology investment addresses and responds to business requirements laid down by both internal or external requirements.
Once I have covered the fundamentals, I’ll discuss what Oracle is doing to help customers achieve maximum availability.
Before we get into that, let’s up-level this and make a few statements. Technology does not drive revenue, it supports it. Technology is here to provide a mechanism to support revenue, directly or indirectly. It can help manage risk, reduce complexity, re-align costs in line with the financial management practices of the company, drive efficiency, scale and increase the speed of operation. So, when we talk about failover services, we first start with the business.
The first question I will always ask with the request for High Availability/Disaster Recovery (HA/DR) is regarding the Service Level Agreements (SLAs). As each loss of service will have its own specific impact to the business should be unavailable you need to understand the explicit cost of operation and the cost to the business, monetary and other, should it become unavailable? Each service has different RPO (recovery point objective) and RTO (recovery time objective) and businesses need to evaluate and agree on these before the topic of resiliency is addressed.
Another point is the segmentation of all your services. With Oracle, you can enjoy line-of-business applications such as ERP, HCM, Cx interconnecting seamlessly with Platform services; Integration, Data Management, Application Development, Analytics, Security to name a few. Each service will have an availability statement around it, and normally, they will be different from the application SLAs, though not always.
Before we think about what type of HA or DR service you need, first you need to think about the risk and cost to your business should the service become unavailable.
Risk management is a large topic in its own right and within this blog, we will not cover the myriad of dimensions but merely to call out risk in the concept of service protection. Your risk and compliance team will be able to guide you on your internal policies, but for you, understanding the business needs surrounding the Cloud Services, in general, will help you narrow down what types of availability requirements you need.
And then there are external regulatory bodies that act as a compliance wrapper for certain businesses or organisations. Often these regulatory directives will call for the ownership and management of people’s data and when PaaS and SaaS support frontline public services; adding a different dimension to how businesses manage and protect the data as well as the interactions and thus will need to be evaluated.
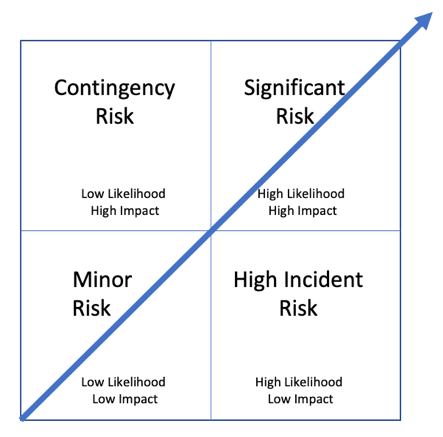
A useful way to start to understand the risk and impact is to chart your services and the impact and likelihood of them failing. The above methodology framework is well known and well used when it comes to quantifying and categorising risk; comparing the likelihood of occurrence with the impact of occurrence. This is an important aspect because the dimension you will also need to understand is what is in place today, that provides resiliency; both in architecture and process. By looking at the likelihood of services or architecture failing will and should complement the discussion on risk management for the business.
Once you have catalogued the availability requirements you will need to think about the cost to the business if the service is unavailable. The cost will be known as a fully burdened cost. Consider the material impact of the service not in operation, but also the time lost in not having it online. Once you have this figure, this will be your benchmark to compare the cost of investment to protect and make the service highly available.
Now, with the respect to availability types, I have heard customers open with “I need five-9’s’” (99.999%) availability for everything. The response to this question is to clarify the need for only 5 minutes, 15 seconds or less of downtime in a year! And if you are thinking so what is “six-9’s”, well that is 32seconds of downtime per year. And when I say downtime, this means service down and failover to an alternative location.
We are now in the realms of data replication, network re-pathing, application re-pathing and other associated dependencies needed to move an entire service line from one location; physical rack or to another Datacentre in another country or region. This all adds costs to operation, known in accountancy terms as OPEX (Operational Expense).
There always needs a balance and you need to be thinking of the economic factors in decisions around technology. If it costs more than the risk of loss, you need to ask whether it is worth it?
Ok, now we have covered the business risk dimension, let’s explore what Oracle is doing to help customers maintain availability, increase speed of operation and scale. The level of innovation that we are doing here is truly amazing. Last year we had the launch of the Autonomous Database, that has in-built machine learning to eliminate human labour associated with Database tuning, security, backups, updates and other routine management tasks that would normally be done by DBAs. This innovation further continues in all aspects of the Oracle offering from Applications, with inbuilt AI right through to the next generation best in class datacentre, Oracle Cloud Infrastructure (OCI). OCI supersedes our first offering; known now as OCI Classic (OCI-C) and it is here I will start to focus this blog and the topic of service resiliency and service availability.
When looking at OCI (our generation 2 cloud), we stopped and thought “What if you could build the cloud over again? What could be done better today? What opportunities and advantages exist in new technology and approaches?”
These were the types of questions we looked at long and hard before even starting to think about architecture. We started with our customers and their business needs and most importantly the protection and security of their data.
We had Security at the heart of the design process while making sure there were rock-solid reliability and the right management tools and processes to support large complex deployments, and to make it as flexible as it was technically possible to give you, the customer the choice on how your environment is deployed.
The performance was another key design principle, but also availability. We looked at building as much resiliency and protection into the physical infrastructure we wanted the Availability by default and not by request because we know your data and service means your operation and if you can’t operate, well, you know the rest.
So, the Oracle Generation 2 Cloud; is the most available, secure and performant cloud infrastructure currently available and we are quite proud of this accomplishment.
Back on the topic of do you need HA/DR for PaaS, let’s look at the standard architecture of OCI.
First off, we deploy our cloud services in Datacenter Regions. In each of these regions, there are at three fault-tolerant independent Availability Domains. Each of these ‘Availability Domains’ contains an independent datacenter with power, thermal and network isolation and thus, do not share resources. Low latency and high-bandwidth interconnects enable zero-data-loss architectures for applications like Oracle Database and high availability for scale-out technologies like Cassandra. Our flat and fast network provides the latency and throughput of rack adjacency across the whole network, allowing synchronous replication and constant uptime. We interconnect Oracle Cloud Infrastructure regions with high bandwidth, fault-tolerant networks achieving > 99.95% reliability (<5 packets lost in 10,000). Interconnecting regions provides consistent latency (as low as 75ms within the US and as low as 75ms US to EU).
Oracle Cloud Infrastructure is the first cloud platform to take network and block IO virtualization out of the software stack and put it in the network, where it truly belongs.
As a result, for the first time, you can provision truly elastic and self-service.
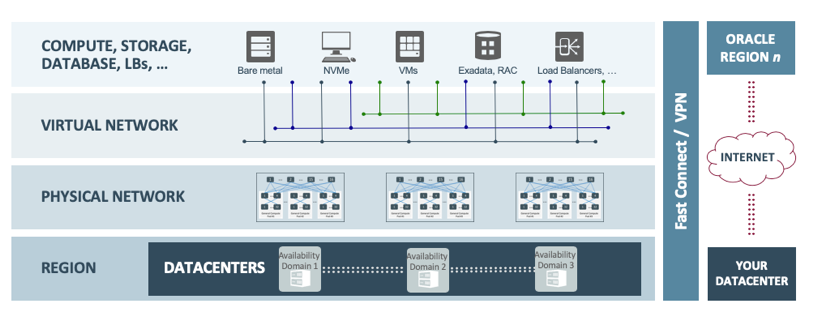
As enterprise High Availability is at the heart of the architecture of OCI and to better understand the Availability Domain architecture we’ll cover this and another availability service, called Fault Domains (FD).
Using one of 3 different Availability Domains (AD) will ensure high availability, as an outage in one AD won’t impact another.
If you would like to segment the services further, you can use the fault domains. A Fault Domain is a granular capability that every customer has access to when they deploy Virtual Machines, Bare metal Instances or PaaS in our OCI datacenter.
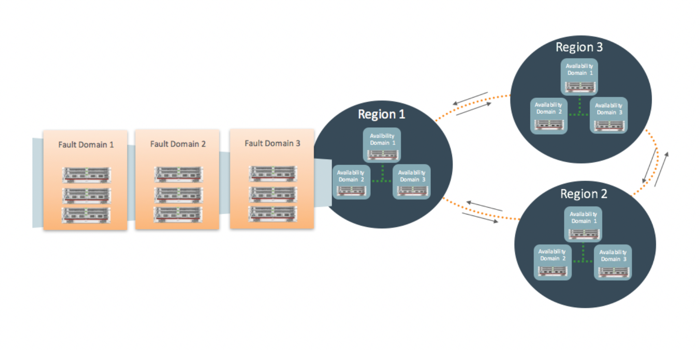
Each Availability Domain will have 3 Fault Domains. A Fault Domain is a consortium of hardware and infrastructure that resides within each Availability Domain and is independent
From each other. By distributing your instances across fault domains, further adds protection to your PaaS Services. Each fault domain will have redundant infrastructure further providing resiliency.
At Oracle we have invested our time and resources to make sure that the underlying architecture is resilient and performant, however, we appreciate that resiliency at the infrastructure layer may not be enough for every business. Before you do start to look into making services available across the Availability Domain infrastructure do look into the Availability and Fault Domain architecture to see whether that level of protection would suffice operations. Some of our customers that have requested HA/DR have ended up not configuring the Services for failover to another location. The Infrastructure resiliency provided by Oracle in OCI met the SLA and protection needs, in-line with the business’s IT risk profile for the services. It was the repeat of this request, that was the stimulus for this blog; highlighting the benefits of the next-generation cloud datacenter, rather than employing a traditional on-premise monolithic-architecture of making every service highly available.
However, sometimes you will need to explore stretched or failover services across datacentres. Sometimes the types of services will require this, especially if tied to the line of business cloud applications, that are protected by availability SLAs. When you deploy end to end SaaS and PaaS in an Availability Domains, distributing instances across multiple Fault Domains gives the services the correct separation from each other.
If you would like to know more about the failover SLAs, please see: Oracle Maximum Availability Architecture (MAA) https://www.oracle.com/database/technologies/high-availability/maa.html
Ok, so what happens, well, if something happens, you may ask? When running your services in a Fault Domain, and, if component-hardware degradation occurs, cloud operations are notified, then the services can be moved from one fault domain to another. This can be done via a migrated re-boot of the Virtual Machine, in a controlled and coordinated way.
Cloud Operations will see the fault through the event monitoring process, then the customer can be notified should the service be degragated.
This is a standard approach for patching and updates that require a systems re-start. Once the system is restarted it will move to another fault domain. There will be an element of downtime to stop and re-start the services, but this needs to be reviewed in-line with the SLAs as I mentioned in the opening paragraphs.
Discussing SLAs again, you will need to verify the migrated reboot time in-line with your acceptable SLA metrics. If this is the case, you may not need a separate HA solution, for local DC fail-over. To instigate a migrated re-boot, this can only be performed by Oracle and the route to achieving this would be to open a Service Request to have this done. If you need to have PaaS in a failover configuration, you will need to verify that the specific PaaS Service can be configured to have a redundant; known as a passive instance, configured in the target availability/fault domain. For this, you would need a VM configured in an offline, ready to be brought up in the event of a domain failure. One option to do this is cloning the Boot Volume and keeping it in an offline state, should a site become unavailable. You will be able to do this and create a clone from the boot volume in the ‘OCI Block Volume Service’. By taking a clone over a backup, will create a single point-in-time copy of the instance without having to go through a recovery/restore process. Another great benefit of using a clone is that you can test and plan for recovery, or test any changes you wish to make, before deploying. Creating a clone instead of using a backup to recovery may incur a slightly higher cost; as the storage location for the clone will be on a Block Volume, whereas a Volume backup will be on Object Storage, but the time to resume service will be quicker. This, again, points to the SLA’s and cost vs risk profile that your services have.
Each Oracle PaaS has its internal architecture which is different to the next and therefore each service will need to be reviewed independently to better understand what can be achieved inline with your SLAs. Going back to the types of failover times initially discussed in this blog, you will need to look to map in your RPO and RTO with the capability of the available solution to verify you will deliver resiliency in-line with your business requirements.
Originally written in 2019, re-publishing with amendments/updates.
