I’ve talked about the subject of long lived TCP connections and load balancers for years, explaining to people why they may not need or want to use a load balancer between two servers. Each time I explain it I remind myself that I should probably write it down so I can just point to the URL.
So today is the day that I write it down for you.
Before we get into the guts of this we should start by defining a couple of terms:
By long-lived connection I mean TCP connections that are opened once and then used for tens of minutes, hours or even days. Basically any connection that you don’t open, use for a few seconds and then tear down.
By load balancer I’m talking about the network device that tries to balance load by twiddling with those connections at the TCP layer. I’m (mostly) excluding things like HTTP reverse proxy servers that terminate the TCP connection and then proxy the request along.
OK, now with that out of the way we can get into the guts of the situation…
Imagine you have one client, one load balancer, and two servers sitting behind it. Something like this:
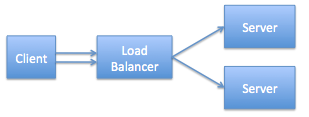
When you do this sort of thing the client is configured to talk to only one IP address – that of the load balancer. Any connections a client opens to the load balancer are automatically and transparently passed through to the servers on the right. In almost all instances the client doesn’t know that it’s talking to two different servers – it just has one IP address after all.
In the diagram above I had the client open two TCP connections and the load balancer sent one to each of the servers. This is perfect – assuming all things are equal each of the servers will get about half of the “load”. As you add more connections from client to server the load should still be pretty evenly distributed.
Now let’s take one of the servers offline for maintenance, because of a hardware problem, or maybe because someone kicked over a power cord. Our little network now looks like this:
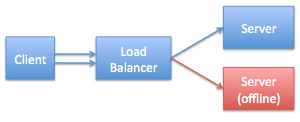
A few moments later the client should figure out that the connection is bad. Because of the way TCP works if the server went down “ungracefully” the first indication that the connection is bad won’t actually come until the client tries to send some data over that connection. The data goes out and, when the TCP ACK never arrives, the OS percolates an error back up to the app.
And here’s where we run into our first problem. Smart-ish clients will keep a list of all of the addresses they’re talking to along with a “State” for those servers. When a connection to “Server X” goes bad the client knows that all of the other connections to “Server X” are suspect and should be checked; it can pull them out of its connection pool check them all and add them back if everything’s OK. While it’s doing that testing the client can keep on using all of the other connections in the pool (they point to the other server after all!). The problem is that when you use a load balancer the client only knows about one IP address – that of the load balancer. So now the client has to know to turn off those those smarts and instead treat each connection independently. As a result when it encounters a problem with one connection the client has to treat every connection as suspect and it needs to go check them all. Or worse if the client might be coded to think all of the connections are bad and tear them all down.
The side effect of this is that without a load balancer the client would be able to keep on going sending requests on the “good” connections without pausing. But with the load balancer the client has to pause processing requests for at least a moment to try to find a “good” connection in its pool or open a new one. In the meantime any requests have to be queued up.
OK, now let’s fast forward a couple of seconds. The client has figured out that connection two was bad, it tears the connection down and opens a new one. Since only the top server is online the load balancer passes that TCP connection to it. So our little network looks like this:
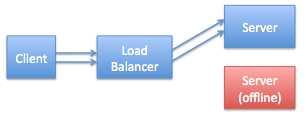
Again this is fine – the top server is getting all of the load but since it’s the only one online that’s all we can do.
Now let’s bring that server back online, wait a few minutes, and take a look at our network.
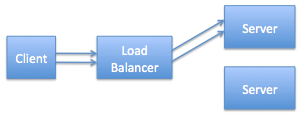
Hmm. We seem to have encountered problem #2 – all of the connections are stuck on the top server and the other server is sitting there twiddling its thumbs. If we wait a few more minutes that won’t change. If we wait an hour it won’t change. In fact no matter how long we wait until something else happens in the environment the situation won’t change – the existing connections stay “stuck” to the top server.
Why?
This goes back to the fact that those connections are “long lived”. The client has been told to open two connections, it did it, and it keeps on using them until they go bad. Since it doesn’t know that is more than one server behind the IP address it has no reason to tear those connections down and open new ones to rebalance the load.
So how can we fix this?
There are a bunch of solutions to this problem but I’m only going to talk about a few obvious ones.
The simplest solution is to make the connections not be long lived. If we opened a new connection for each request we wouldn’t have this problem. Performance would be worse, though how much worse depends on what constitutes a request. But we don’t have to make that dramatic a change to fix our problem. Rather than making each request use a separate connection we could reuse the connection for some period of time or number of requests and then tear it down. When the second server comes online it won’t get traffic immediately but over time the law of large numbers will kick in and cause load to balance out automatically. For example allowing connections to live for no longer than 10 minutes means that about 10 minutes after you bring the second server online the load should be back to being balanced. of course the more connections you have the truer this example is!
Another solution to the problem is to have the Load Balancer intervene to force the connections to rebalance. Some load balancers allow you to configure the load balancer to poll the servers. When a server comes online the load balancer will become aware of that and it could forcibly reset some of the existing connections by sending a TCP RST packet to the client. The client will then know that that one connection has gone “bad” and it can open new connections to the server. This solution is much more intrusive than the first one – it requires the load balancer to preemptively monitor the servers and to figure out which existing connections to terminate. To do this correctly the load balancer may need to understand the wire protocol – a server might be listening on the TCP socket and be able to accept the connection but the software could be hung. As a result I tend to toss this solution into the “too smart by half” pile.
A third solution is also intrusive, but the intrusion happens inside the protocol. The problems above stem from the fact that the client doesn’t know that there are multiple servers behind the load balancer, it doesn’t know which connections go to which server, and it doesn’t know which servers are online. If we just tweak the protocol so that the initial handshake says “hello client, I’m ‘server X’, nice to meet you” the client will have half of what it needs. Add a “which servers are in the cluster and what is their state” that the client can call every once in a while and you’ve neatly solved the problem. With those two bits of info the client has everything it needs to deal with problems, detect imbalances, and rebalance when servers go offline or come online. Of course we’ve added even more complexity to solve the problem, so again probably too smart by half!
As useful as load balancers are sometimes it’s better to leave them out of the picture. If your client uses long-lived connections and already knows how to deal with multiple servers you might be better off just letting it do that itself. It’s usually easier to setup, troubleshoot, and it leaves one extra layer of complexity out of your environment.
