Introduction
In the world of cloud computing, buzzwords like High Availability (HA), Disaster Recovery (DR), and Reliability often get thrown around—but what do they actually mean, especially in the context of Oracle Cloud Infrastructure (OCI).At first glance, they may sound interchangeable—after all, they all deal with keeping your systems up and running. But in reality, each plays a unique and critical role in ensuring that the applications and data are always available, secure, and recoverable.
Objective
To clarify and distinguish the key concepts of High Availability (HA), Disaster Recovery (DR), and Reliability within Oracle Cloud Infrastructure (OCI). This blog aims to offer a reader-friendly, insightful guide using everyday comparisons, visuals, and practical examples that make these technical ideas easy to grasp. The goal is to help cloud professionals and tech enthusiasts understand how each approach supports system uptime, resilience, and business continuity—empowering them to design stronger, more dependable cloud architectures in OCI.
In today’s always-on digital world, downtime is expensive—not just in terms of lost revenue, but also in customer trust, brand reputation, and operational disruption. Whether an organization is dealing with planned outages—such as routine maintenance, security patching, or system upgrades—or facing unplanned disruptions like power failures, hardware breakdowns, software bugs, or network outages, the need for a highly available and reliable architecture remains the same. Without built-in resilience and recovery mechanisms, even scheduled downtimes can become disruptive and risky. Systems should be designed to gracefully handle maintenance events without user impact and to recover quickly from unexpected failures—ensuring continuity, minimizing risk, and preserving user trust.
Let’s now delve into the comparison of High Availability, Disaster Recovery, and Reliability.
High Availability(HA)
High Availability (HA) in OCI ensures minimal downtime and system resilience by distributing workloads across multiple Availability Domains (ADs), Fault Domains (FDs), and Regions. OCI provides several services to achieve HA at the compute, database, networking, and storage levels.
Key Concepts of HA in OCI
- Fault Domains (FDs): Logical groupings within an Availability Domain (AD) to prevent single points of failure.
- Availability Domains (ADs): Physically separate data centers within a region.
- Load Balancing: Distributes traffic across multiple instances for fault tolerance.
- Auto Scaling: Dynamically adjusts resources based on demand.
- Redundancy & Failover Mechanisms: Ensures backup resources take over when failures occur.
OCI HA Native services
Compute HA Services
|
Database HA Services
| OCI Service |
HA Features |
| Oracle Autonomous Database |
Built-in HA with automatic failover and backups. |
| Oracle Data Guard |
Data Guard can be configured to automatically switch to the standby database in case of a failure in the primary database. |
| Oracle RAC (Real Application Clusters) |
Multi-node DB for active-active HA. |
Storage HA Services
| OCI Service |
HA Features |
| OCI Object Storage |
Data automatically replicated across ADs for durability. |
| File Storage Service (FSS) |
Distributed storage across ADs for HA. |
Network HA Services
| OCI Service |
HA Features |
| OCI Load Balancer |
Ensures traffic distribution across multiple servers. |
| OCI FastConnect & VPN |
Redundant private connections for HA. |
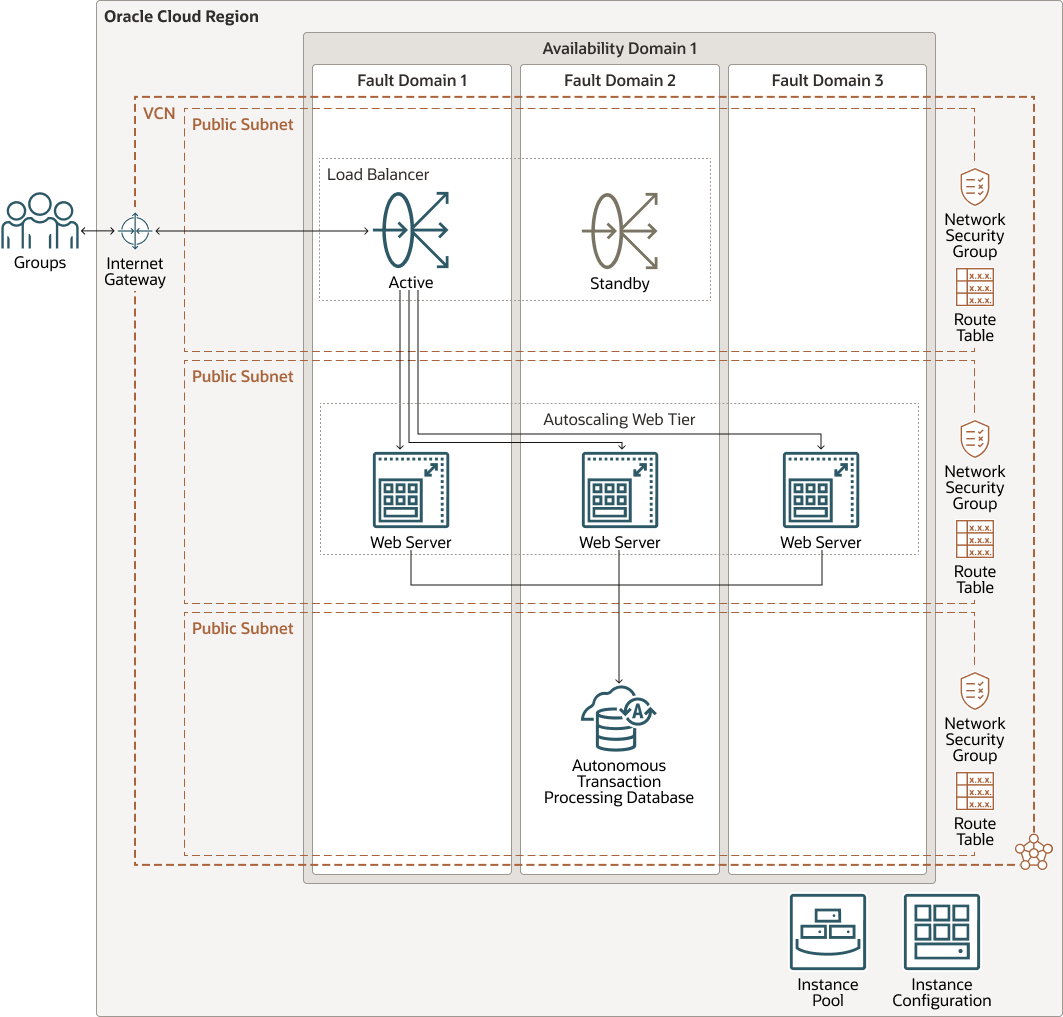
Sample Architecture diagram:
The architecture is designed for High Availability (HA) by distributing critical components across multiple fault domains, minimizing the risk of a single point of failure. This infrastructure includes a tier of web servers and an Autonomous Transaction Processing (ATP) database.
To ensure resilience and uptime:
- Web servers are strategically placed across multiple fault domains, allowing the system to remain operational even if one domain becomes unavailable.
- Load balancers are deployed in active-standby mode, directing incoming traffic efficiently while ensuring failover capabilities in case of a primary balancer failure.
- Autoscaling is enabled to automatically adjust the number of web server instances based on real-time traffic demands, maintaining performance under varying loads.
This architecture ensures that services remain accessible, responsive, and fault-tolerant—even during component or domain-level failures.
MAA Best Practices for the Oracle Cloud: https://www.oracle.com/database/technologies/high-availability/oracle-cloud-maa.html
Disaster Recovery (DR)
To ensure business continuity and data recovery in the event of catastrophic failures—such as natural disasters, major infrastructure outages, or region-wide service disruptions—a robust Disaster Recovery (DR) strategy is essential This can be achieved using multiple region deployment as well as Backing up the storage with replication enablement.
The goal of DR is to ensure business continuity by minimizing downtime and data loss through backup solutions, redundancy, and failover mechanisms—often involving secondary sites or regions.
Key OCI Services for Disaster Recovery
| OCI Service |
DR Purpose |
||
| Object Storage Cross-Region Replication |
Replicates object storage across OCI regions. |
||
| Block Volume Replication |
Syncs storage volumes between primary & DR sites. |
||
| Oracle Data Guard |
Data Guard can be used to create a standby database in a separate region for disaster recovery. |
||
| Oracle GoldenGate |
Active-active database replication across regions. |
||
| Traffic Management (DNS Steering) |
Automatically redirects traffic to a DR site in case of failure. |
||
| FastConnect & VPN |
Ensures redundant connectivity between on-premises & OCI. |
||
| DB Autonomous Recovery service |
DB will be backed up with zero data loss |
Choosing the Right DR Strategy
| DR Type |
RTO (Recovery Time Objective) |
RPO (Recovery Point Objective) |
Cost |
Use Case |
| Backup & Restore |
High (Hours) |
High (Up to 24 hours) |
Low |
Archival, Non-critical workloads |
| Active-Passive (Warm DR) |
Medium (Minutes-Hours) |
Low (Minutes) |
Medium |
Web Apps, Enterprise Apps |
| Active-Active (Hot DR) |
Low (Seconds-Minutes) |
Near Zero |
High |
Banking, E-commerce, Financial Services |
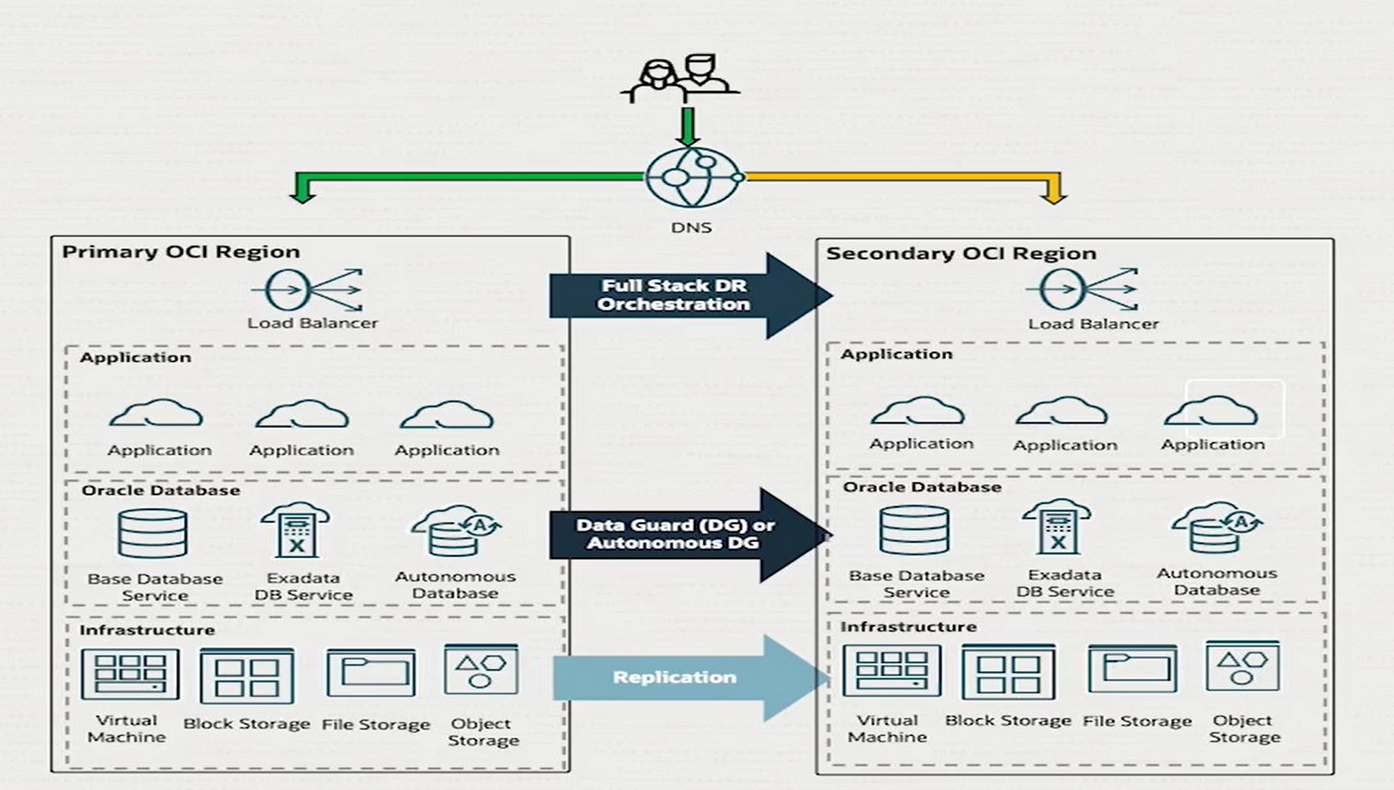
Sample Architecture Diagram
The architecture diagram illustrates a comprehensive Disaster Recovery (DR) setup designed to ensure business continuity in the event of regional outages or catastrophic failures. The infrastructure spans two geographically separate regions—designated as Primary and Secondary—to provide redundancy and fault tolerance.
Key components include:
- Application servers and databases deployed in both regions to support failover scenarios.
- Primary and secondary load balancers are configured to route traffic to application servers, with failover capability in case the primary region becomes unavailable.
- Oracle Data Guard is enabled between the primary and secondary databases, ensuring real-time database replication and disaster recovery.
- All supporting infrastructure services, such as storage, object storage, and file systems, are replicated to the secondary region, enabling data backup, consistency, and quick restoration.
This setup provides a resilient and scalable architecture that safeguards against data loss, reduces downtime, and enables rapid recovery across regions during disaster events.
Full Stack DR : https://blogs.oracle.com/cloud-infrastructure/post/fsdr-news-2025-05
Reliability
The ability of a system to consistently perform without failures over time will lead to System stability, durability, and resilience. Reliability ensures long-term stability by combining HA + DR + Monitoring for an always-available system. It’s a broader concept that ties together high availability and disaster recovery, but focuses specifically on consistency and trustworthiness of the infrastructure.
Key OCI Services for Reliability
OCI provides multiple layers of reliability, including compute, database, storage, networking, and monitoring services.
Compute Reliability
| OCI Service |
Reliability Features |
| Fault Domains (FDs) |
Protects workloads by distributing across separate hardware. |
| Auto Scaling |
Automatically adjusts resources based on demand. |
| Oracle Kubernetes Engine (OKE) |
Deploys highly available containerized workloads. |
| Load Balancer |
Ensures traffic is distributed across multiple instances for fault tolerance. |
Database Reliability
| OCI Service |
Reliability Features |
| Oracle Autonomous Database |
Self-healing, auto-scaling, auto-patching. |
| Oracle Data Guard |
Disaster recovery and failover for databases. |
| Oracle GoldenGate |
Multi-region, active-active database replication. |
| MySQL HeatWave |
High-performance analytics with built-in HA. |
Storage Reliability
| OCI Service |
Reliability Features |
| OCI Object Storage |
99.999999999% (11 nines) durability, automatic replication, backup , custom backup and replication using rclone. |
| OCI Block Volume Replication |
Synchronous and asynchronous storage replication. |
| File Storage Service (FSS) |
Distributed storage across availability domains. |
Networking Reliability
| OCI Service |
Reliability Features |
| Load Balancer (LB) |
Automatic traffic routing to available instances. |
| Traffic Management (DNS Steering) |
Automatically redirects traffic to a healthy region. |
| FastConnect & VPN |
Redundant network paths for failover. |
Monitoring & Observability
Operations and Maintenance (O&M) encompasses the ongoing tasks required to manage, monitor, and maintain cloud infrastructure and applications after initial deployment. In OCI, this includes ensuring uptime, applying patches, optimizing resources, securing data, and responding to incidents.
1. Monitoring & Observability
- OCI Monitoring: Collects metrics from compute, storage, and network resources.
- OCI Logging: Captures logs from services, enabling real-time troubleshooting.
- OCI Alarms: Automatically triggers actions or notifications based on metric thresholds.
2. Patch Management
- OS Management Service: Automates patching and updates for compute instances.
- Autonomous Database: Applies patches automatically without downtime.
- Managed services: Many OCI services handle patching behind the scenes.
3. Backup & Recovery
- OCI Object Storage: Used for backups with versioning and lifecycle policies.
- Block Volume Backup: Automated and manual backups for attached storage.
- Database Backup & Recovery: Configurable backup policies for Oracle DB and ATP.
4. Security Operations
- OCI Vault: Stores and manages keys and secrets securely.
- Identity and Access Management (IAM): Manages user permissions and roles.
- Cloud Guard: Detects misconfigurations and threats.
- Security Zones: Enforce security policies automatically in specified compartments.
5. Resource Optimization & Cost Control
- Usage Reports & Budgets: Monitor consumption and set cost limits.
- Autoscaling: Automatically scale compute instances based on demand.
- Tagging & Resource Governance: Organize, track, and control resource usage.
6. Incident & Change Management
- Support Integration: OCI integrates with Oracle Support for incident escalation.
- Change Logs: Audit logs help track changes for compliance and troubleshooting.
| OCI Service |
Reliability Features |
| OCI Monitoring & Alerts |
Detects performance issues before failures occur. |
| Logging & Audit Logs |
Tracks system health and security events. |
| Service Health Dashboard |
Displays real-time OCI service status. |
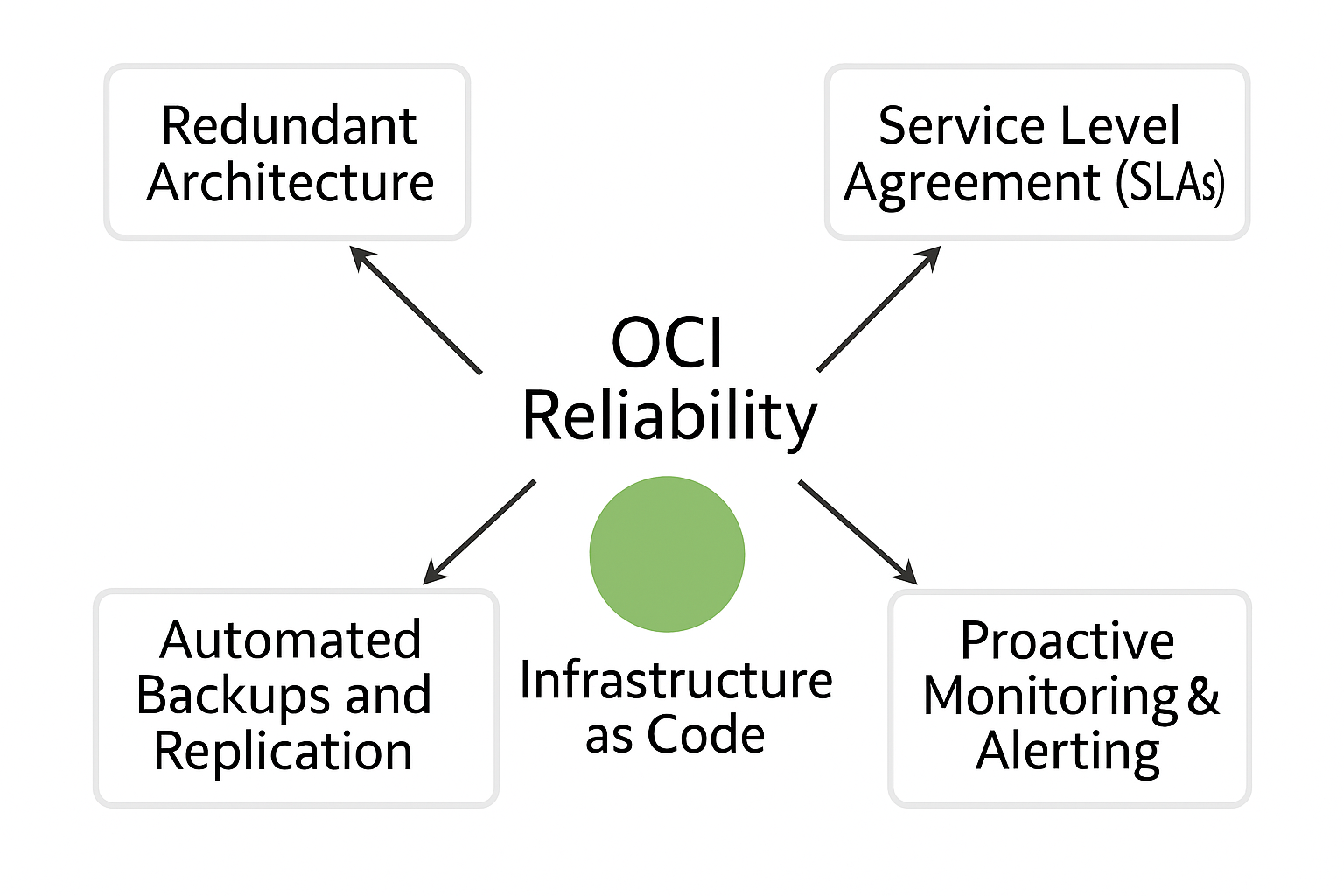
Sample Architecture Diagram
The following Architecture Diagram illustrates the key features and components that need to be considered when building a reliable infrastructure in Oracle Cloud Infrastructure (OCI).
- Redundancy: Distributed resources in different regions and Availability Domains.
- Failover: Seamless failover mechanisms through load balancers and disaster recovery setups.
- Autoscaling: Automated scaling of compute resources based on demand.
- Backup and Recovery: Replication and backup strategies to ensure quick recovery.
- Security: IAM and Oracle Cloud Guard for securing resources and ensuring reliable access control.
- Monitoring: Real-time performance monitoring with automatic alerts and proactive issue handling.
- Service Level Agreement : Oracle provides SLAs for many of its cloud services, each specifying key metrics like availability, uptime, and support response times
https://www.oracle.com/contracts/docs/paas_iaas_pub_cld_srvs_pillar_4021422.pdf?download=false
https://www.oracle.com/in/cloud/sla/
Conclusion
HA keeps services running with minimal disruptions within a single region.
DR ensures business continuity by enabling a failover strategy across regions.
Reliability is the broader concept ensuring consistent, error-free performance of services.
| Feature |
High Availability (HA) |
Disaster Recovery (DR) |
Reliability |
| Objective |
Minimize downtime in a region |
Recover from catastrophic failures |
Ensure long-term system performance |
| Scope |
Within a region (Availability Domains, Fault Domains) |
Across regions (Geo-redundancy, backups) |
Covers both HA & DR with focus on stability |
| OCI Services |
Fault Domains, Load Balancing, Multi-AD Deployment |
Cross-Region Replication, Data Guard, DR Plans |
Monitoring, Logging, SLAs, Backups |
References
https://docs.oracle.com/en-us/iaas/Content/cloud-adoption-framework/disaster-recovery.htm
https://docs.oracle.com/en-us/iaas/Content/cloud-adoption-framework/high-availability.htm
https://docs.oracle.com/en-us/iaas/Content/cloud-adoption-framework/extreme-reliability.htm
https://docs.oracle.com/en-us/iaas/Content/Monitoring/Concepts/monitoringoverview.htm
Networking References
https://docs.oracle.com/en-us/iaas/Content/Resources/Assets/whitepapers/ipsec-vpn-best-practices.pdf
https://docs.oracle.com/en-us/iaas/Content/Network/Concepts/fastconnectresiliency.htm
https://www.ateam-oracle.com/post/oci-networking-best-practices—part-3—oci-network-connectivity
https://www.youtube.com/watch?v=PwKS4NpuUKg
