Over the past several months prior to writing this blog, I have had a number of discussions with customers on how they can improve the speed of mining information across their data architecture.
Customers are expressing that they are attempting to harness their data, though it is often challenging when it is siloed and fragmented across different systems/services both on premise, or in the cloud. This data-chaos is leading to several challenges that organisations need to navigate.
One of the issues being faced, is the slow speed of data delivery. In traditional data management approaches, data analysts and data scientists have to wait for IT teams to provision and configure data infrastructure, which can take weeks or even months. This delay hinders the ability to analyse and derive insights from the data, which can have a direct impact on business operations and decision-making.
Another challenge we see are the complexity of data pipelines. Data is often stored in multiple sources, and the process of extracting, transforming, and loading into a data warehouse or data lake can be challenging, error-prone, and time-consuming. The ETL process requires coordination between multiple teams with different skills, such as data engineering, data integration, and data quality management.
Making sure that data is of quality is another significant challenge that organisations face. Poor data can lead to inaccurate insights, which can have severe consequences for business operations and decision-making.
And then there is regulatory compliance. This is an increasingly critical challenge for organisations. Regulations such as GDPR and CCPA have placed stringent requirements on how organisations handle personal data, and failure to comply with these regulations can result in significant fines and reputational damage.
The evolution of analytics.
Making sense of data and turning it into valuable insightful information has always been a focus for organisations. Having the ability to mine data sets to derive themes to make decisions has always been a priority. However, traditional approaches have been present/past orientated, looking at to what has happened. These are often charactered as Diagnostic and Descriptive.
- Diagnostic is examining content/data to answer a question of why something happened.
- Descriptive aims to parse data to help with why certain changes occurred.
The analytic landscape has matured via the acceleration of machine learning development. What we can do now is add forward looking analytics to the current approach. These emerging areas help us to build Predictive and Prescriptive analysis.
Moving the analysis from insights to decision and then action, Predictive analytics helps one make sense of data created from past events, to attempt to make predictions about the future by using machine learning/data mining and statistical modelling practices.
This form of analysis helps with decision making, however, there will be a choice that a human will need to make.
Prescriptive analytics on the other hand, tries to answer the question ‘what should I do?’. Prescriptive analysis uses data, mathematical models, and optimisation techniques to provide recommendations or solutions for complex business problems. It considers different constraints and objectives to identify the best course of action among multiple options.
Predictive and Prescriptive analysis is often used in decision-making processes where the consequences of each decision are evaluated to determine the optimal solution.
Figure 1 below shows how advanced analytics broadens the analytic landscape by encompassing future analysis as well as the traditional rear-view approaches.
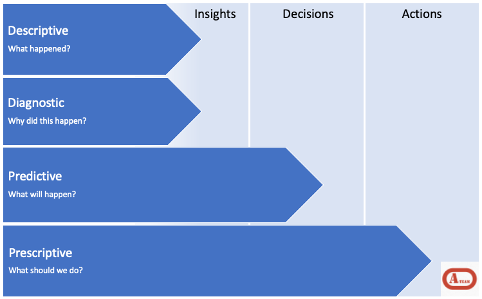
Figure 1
Ditching data silos by adopting a modern data platform approach.
Though there are many ways to mine information to derive insight to action, we are finding organisations still struggle to make use of the full spectrum of information. This is often because their data is siloed and there is no underlying way to unify it all to make sense of it.
Enter the Lakehouse! In an attempt to put some structure around the data landscape, the Lakehouse, as modern data platform initiative for one, is starting to gain an element of popularity. The Lakehouse approach allows organisations to run the required algorithms needed to move into both Predictive and Prescriptive analytics.
If you are not familiar with the Lakehouse approach, please see my previous blog: https://www.ateam-oracle.com/post/a-cios-checklist-in-building-a-modern-data-platform
But in summary, a Lakehouse architecture is a data management framework that combines the best features of data lakes and data warehouses. It offers a unified data platform approach that enables organisations to manage both structured and unstructured data at scale.
One of the key benefits of the Lakehouse architecture is that it allows organisations to store large volumes of raw data in a cost-effective and scalable manner. This raw data can then be transformed and processed using various analytics tools and frameworks, including SQL, Apache Spark, and machine learning, thus enabling organisations to perform complex analytics on their data, such as predictive modelling, machine learning, and natural language processing.
The Lakehouse architecture is enabled by using a centralised Data Catalog and governance framework that ensures data consistency, accuracy, and quality across the organisation. The idea, and the premise of a Lakehouse is that it makes it easier for data an
alysts and data scientists to access and analyse data from different sources, without having to worry about data quality or inconsistencies.
Figure 2 taken from my blog, referenced above.
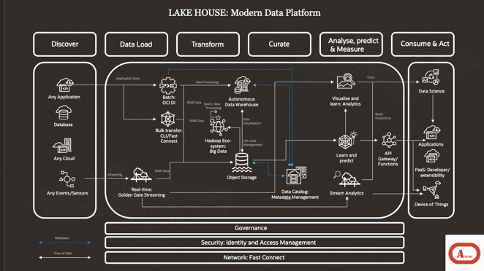
Figure 2.
However, technology alone won’t solve the problems. People and processes that underpin the Lakehouse are needed.
- People. The mindset around data needs to change, which starts with adopting a culture of progression. Data is not a one-time perspective that you store, for a just in case event; information, which in my mind is interpretating data to create a perspective, evolves and therefore the approach data needs to be thought of endless.
- Processes. To formulise the continuous culture of data, processes need to be adopted/amended to help deliver an automated approach of constant access to data. Data scientists need seamless access to data, and getting it loaded is key. If this is your first outing to data science and big data, you may gloss over data loading as a simple task. Well, it is one of the biggest blockers. Getting data and loading it is not easy in many cases. See my co-authored blog on ETL vs ELT for some context: https://www.ateam-oracle.com/post/etl-vs-elt-architecting-a-modern-data-platform-for-high-demanding-data-services
If you have some exposure here, and you think that all this can be covered through machine learning operations (MLOps), you would be right (to a point), as the purpose of this approach enables the deployment of machine learning models reliably, and effectively to production environments.
But to make this work, you need the collaboration found within the structure of DevOps. To make sense of information and perform advanced analytics, you need to blend both MLOps and Dev Ops together. When we do, we get DataOps!
DataOps.
The organisations that have managed to get to grips with advanced analytics and have done so not just by pulling together their data sources, they have adopted the DataOps methodology.
DataOps has emerged in response to the increasing complexity of data management and the need for greater agility and efficiency in the processing of data pipelines especially for performing machine learning.
In essence, the goal of DataOps is to improve collaboration, communication, and integration between different teams involved in the data processing pipelines, including data engineers; data scientists; and business analysts.
By embracing a DataOps approach, those organisations have reduced the time to market for data-driven solutions, improved their quality of data for analysis, and increase the efficiency of their data processing pipelines.
This is because DataOps focuses on implementing data validation checks, monitoring data quality metrics, and ensuring that data is properly documented and managed. This practice enables organisations to automate their ETL processes, making it faster, more reliable, and less prone to errors.
With the organisations we have spoken with, each are at different stages with trying to break down the metaphoric barriers that are in place, but one thing is clear, the silos that previously existed are finally being addressed.
DataOps also improves the partnership between data scientists and DevOps teams. With traditional data management practices, data scientists and DevOps teams often work in silos, with little communication or coordination between them. This can lead to delays and errors in the data pipeline. DataOps, on the other hand, encourages collaboration between these two teams, which helps to ensure that the data pipeline is optimised, and that data-driven products and services are delivered to market faster.
Another benefit of DataOps is that it enables organisations to make better use of their data. By automating and optimising the data pipeline, DataOps makes it easier for organisations to access, collect, store, and analyse large amounts of data. This, in turn, enables organisations to gain insights from their data that they might not have otherwise been able to.
Security and governance see benefits too. The DataOps approach includes automated data lineage, data quality and data discovery, which helps to ensure that data is accurate, secure and compliant with various regulations. This is particularly important for organisations that handle sensitive data, such as personal information or financial data.
Putting it into Practice.
Implementing a DataOps strategy can be a complex process, but there are a few key steps you can take to get started:
- Define your DataOps goals and objectives: Start by defining what you want to achieve with your DataOps strategy. This will help you to identify the specific areas of your data pipeline that need to be improved and will guide the development of your DataOps plan.
- Assess your current data pipeline: Take a look at your current data pipeline and identify any bottlenecks or inefficiencies. This will help you to understand where improvements need to be made and will inform the development of your DataOps plan.
- Build a cross-functional team: Create a cross-functional team that includes members from both your data science and DevOps teams. This team will be responsible for implementing your DataOps strategy and will help to ensure that the data pipeline is optimised, and that data-driven products and services are delivered to market faster.
- Automate and optimise your data pipeline: Use automation tools and techniques to optimise your data pipeline. Automation can help to reduce errors and speed up the time to market for data-driven products and services.
- Implement data governance: Implement a data governance strategy that includes automated data lineage, data quality and data discovery. This will help to ensure that data is accurate, secure and compliant with various regulations.
- Monitor and measure progress: Continuously monitor and measure the progress of your DataOps strategy to identify areas that need improvement and to track the effectiveness of your DataOps plan.
- Continuously improve: Continuously evaluate and improve your DataOps strategy and processes. This will help you to stay ahead of new trends and technologies and will enable you to adapt to new business requirements.
DataOps is a set of practices and tools that organisations use to improve the speed, quality, and reliability of data delivery. The importance of having the right DataOps skills lies in the fact that it allows organisations to make better and faster decisions, improve their data-driven processes, and ultimately drive more revenue. With the increasing amount of data being generated by businesses, it is essential to have a streamlined and efficient process for managing and analysing that data. DataOps skills are also important for data privacy and security, as they help ensure that sensitive information is protected and handled appropriately. In addition, having the right DataOps skills allows organisations to quickly identify and resolve data-related issues, leading to fewer disruptions in operations and increased customer satisfaction. In today’s data-driven world, the ability to effectively manage, analyse, and utilise data is crucial for the success of any business. Therefore, having the right DataOps skills is essential for staying competitive and achieving organisational goals.
To run a DataOps team, you would need expertise in the following areas:
- Data management: Knowledge of data warehousing, data modelling, and data governance.
- Data integration: Experience with ETL (Extract, Transform, Load) tools and techniques for integrating data from different sources.
- Data analytics: Knowledge of statistical analysis and data visualisation tools, as well as experience with big data technologies such as Hadoop and Spark.
- Cloud computing: Familiarity with cloud-based data storage and processing solutions, such as Oracle and others, mentioning no names…
- Project management: Experience leading cross-functional teams and managing projects through the entire software development lifecycle.
- Agile, DevOps & MLOps methodologies: Understanding development methodologies and experience working with DevOps practices.
- Strong communication and leadership skills: The ability to communicate effectively with team members and stakeholders, and the ability to lead and motivate a team.
- Advanced knowledge of the domain area the DataOps team is working in.
It’s important to note that a DataOps team could be composed of different roles and not everyone need to be an expert in all areas mentioned above. The leader should have a good understanding of all aspects and how they integrate together to achieve the goals of the team.
Additionally, it is important to note that implementing a DataOps strategy requires a significant investment of time and resources, and it might be hard to do it all at once. It is better to start with small and feasible projects to demonstrate the value and benefits of DataOps and then scale up gradually.
Conclusion
In order to facilitate the adoption of predictive and prescriptive analytics, data pipelines and the processes that surround them can potentially be managed more effectively through the use of DataOps.
Additionally, organisations can improve the efficiency, speed, and agility of their data-driven decision-making by encouraging teamwork when using Machine Learning and by implementing a DataOps strategy.
